プログラミング初心者のアマグラマーがhubot相手に奮闘中
はじめに
こちらはアドベントカレンダー9日目の記事です。
何か書かねばならぬ流れになり、なかなかコーディングのプロになれないアマチュア以下レベルの私が hubot奮闘記 について書こうと思います。 当方Photosynth入社2ヶ月、ぺーぺーQAです。開発エンジニアではないので技術的な部分についてもしかしたら誤りがあるかもしれません。以下の点を予めご了承いただきご一読していただければと。
- 本記事は「これをやったらできた」というログです。技術的な根拠を保証するものではありません
- hubotを動かすための奮闘記です
- hubotのインストール〜セットアップについては触れません
- 実装環境はMac(Mojave)です
背景とここまでの流れ
この記事を記載するまでのざっくりとした背景と流れ(当方視点)は以下の通り
- テスト自動化の話があがっていた
- 諸々検討の末(はしょります)、「自動化」の切り口をテスト自動化に拘らず業務全般(プロセス)に置いた
- 「botを使って誰でも簡単に何かできるようにしたい」という意向があった
- 当社チャットツールはslackを使っている
- 前職で slack & hubot 使ってた(使ってただけで裏側はいじったことがなかった)
- 前職の経験からいろいろと融通が効きそうなhubotを提案してみた
- 提案が通った
- 目的(解決する課題)を定義
- 実装開始
目的(解決すべき業務課題) と 手段(hubotをどう使うか) の設定
目的
↑の2で記載した 何か をどう置くか。その今回は目的部分を「誰でも触れる簡易デバッグツール」にしました。 データ参照という点では将来的にCSさんや営業さんが出先でもslackで一言発言すればユーザー様の利用情報など参照できるようにしたいと考えております(現状はその前段階で奮闘中)。将来的に。 そのための社内APIもhubotとともに実装したりしていますが今回それは別の話。hubot自体に焦点を当てて記載します。
手段
hubotで実現したい要件(ざっくり)は以下の通り
とっても初歩的なhubotの活用術ですね。 それでも当方のようなアマグラマーにとってはなかなかのハードル。あーでもないこーでもないと捏ねくり回しております。

hubothubotっていうけどそもそもhubotって何?
slack(チャットツール)で使えるボットです(ざっくり)。 もう少し詳しく言うと GitHub社が開発しMITライセンスで公開しているNode.jsでbotを作り動かすためのフレームワークです(引用参照)。
要するに チャットツールをちょっと便利にしてくれるツール という認識。
立ちはだかる壁 〜言語問題編〜
さて前置きが長くなりました。ここからが本題です。
早速実装を、、と思ったらこのhubot、coffee scriptなんですよね…
coffee script を0から覚えていくのはいかがなものか、、coffeeとか生理的に受け付けない、、、。
なんとかcoffee回避できないか、色々考えました。
考えてみた その1
coffeeはあくまでhubotとコミュニケーションするためのハブとして使い、別言語の実装ファイルを呼び出して使う
HubotSlack = require 'hubot-slack'
child_process = require('child_process')
module.exports = (robot) ->
robot.hear /^example (.*)$/i, (res) ->
child_process.exec "bash shell/test.sh", ()->
こうすればcoffeeにふれるのは最低限で済む。万事解決......と思いきや。
結果
- そもそもshellで書くってハードル高すぎるだろう…属人化招く一因にもなりうるんじゃね?
- エンジニアさんにも「やめとけ」と首を横に振られた
- じゃrubyで…
- ハブ扱いにすると色々と処理がめんどい
などなど。この現実逃避は失敗しました。
考えてみた その2
流行り(?)のgasと連携させれば良いのでは…?
結果
先のslackのアップデートによりwebhooksの扱いがうんにゃらということで心折られました。(こちらの記事の冒頭部分参照) [slack × hubot × gas]関連はこの記事以前に書かれているものが多く、解決しうる記事が見つからず。 当方の力量では皆様のお書きになられ遊ばれた御ドキュメントのお力添えをなくして実現不可と存じ上げ候。
考えてみた その3
この(coofee嫌いという)問題に遂に決着が付きました。
coffeeのcommandでこんなものが。
$ coffee --compile script/example.coffee
hubotインストール時に example.coffee なるファイルが存在します。hubotはこうやって使えよっていうサンプル用実装ファイルです。
そのexample.coffeeに対して上記のコマンドを実行してみたところ、元ファイルとは別に example.js なるファイルが生成された(歓喜)
しかも生成されたファイルのコード、結構わかりやすい(歓喜)
module.exports = (robot) ->
robot.respond /テスト/i, (msg) ->
msg.send "テスト"
これが
// Generated by CoffeeScript 1.6.3
(function() {
module.exports = function(robot) {
return robot.respond(/テスト/i, function(msg) {
return msg.send("テスト");
});
};
}).call(this);
こう。
ここでは example.coffee を例にしましたが、実際ちょろっと作ってたコードも分かりやすくコンパイルしてくれました。
もちろん .js ファイルでhubotさん問題なく動いてくれます。
こうしてjsで書く方針を固め、実装を開始するのでした。
立ちはだかる壁 〜デバッグ編〜
実装をすすめるにつれ、実挙動を確認しながら実装する = 都度hubotを立ち上げてコード検証を行う のがダr...もといダルくなってきました。
jsコードのデバッグ
jsコードをターミナル上でなんとか実行できないものか。調べてみたらMacには jsc なるものがデフォでインストールされているとか。
jsファイルを jsc hogehoge.js と打つと実行してくれる模様。
使ってみよう
$ jsc --help -bash: jsc: command not found
あかんやん。 パスが通っていない(シンボリックリンクを作る必要がある)ため、Macさんの素の状態では使えないようです。 以下を実行します
$ ln -s /System/Library/Frameworks/JavaScriptCore.framework/Versions/A/Resources/jsc /usr/local/bin
そしてもう一度
$ jsc --help Usage: jsc [options] [files] [-- arguments] -d Dumps bytecode (debug builds only) -e Evaluate argument as script code -f Specifies a source file (deprecated) -h|--help Prints this help message -i Enables interactive mode (default if no files are specified) -m Execute as a module -s Installs signal handlers that exit on a crash (Unix platforms only) -p <file> Outputs profiling data to a file -x Output exit code before terminating <以下略>
出来た(歓喜)。
jsの挙動に詳しくないのでtest.js なる適当なファイルを作って jsc test.js を実行し、変数の中身や振る舞いを確認しながら実装を進めています。こうすることで大分楽になりました。
※ jscでは consol.log() はそもそもの実装がないため使えません。print()を使いましょう。
正規表現のデバッグ
hubotをslack上で呼び出すにあたって、自然言語だとhubotさんが困ってしまうかもしれない(割愛)と思い、 ターミナルでcommandを実行するような挙動にしたいと考えつつ実装をすすめています。 例えばこんな感じ
index device 1000000 # <引数1:command> <引数2:target> <引数3:id> # => idが1000000のデバイスの情報を参照して返す
ここで必要な要件は
- 有効な引数以外の引数が入力されたときは弾く
- コマンドに対して必要な引数の数が不足・超過しているときは弾く
など。
return robot.hear(/(.*) (.*) (.*)$/i, function(msg) {略}
(.*) (.*) (.*) ←ここをしっかり書かねば、、でもいちいち動かして確認はツライ。
そしてたどり着きました.
便利です(歓喜)。 rubyと記載がありますが「正規表現だし関係ねぇ」と思って使ってます。今の所jsの挙動と差異はありません(詳しいことはわかりませんすみません)。
これを基に上記の例でいうと (.*) (.*) (.*) は ^index \w* \d{6} 雑ですがこんな感じかな、、と。皆様もぜひ触ってみてください。
※slackからの引数の活用として以下のように書けば必要以上の正規表現は書かずに済みそうです。 結論、現在はswitch文でカバーの方針に切り替えています。正規表現の扱いに苦労しましたというお話でした(
module.exports = function(robot) {
return robot.hear(/^device (.*)$/i, function(msg) {
var arg = msg.match[0].split(/\s/);
// => ["device","引数2","引数3","引数4",....]
//<以下略>
立ちはだかる壁 〜API編〜
APIを作るのがhogefugapiyoというのも壁ではあるのですが本記事に関係ないので割愛します。 問題は「APIをどうやって叩けばええねん」ということでした。
https://hubot.github.com/docs/scripting/
こちら公式ドキュメントなのですが、 ここの Making HTTP calls を読んでもイマイチわかりません。
やりたいこと
英語をnative言語とするエンジニアさんに助けを請い、以下のようにしないといけないことが分かりました。
結果
参照する場合
module.exports = function(robot) {
return robot.hear(/^device index <id>$/i, function(msg) {
var arg = msg.match[0].split(/\s/);
robot.http("http://localhost:8000/API/device/index")
.header('Content-Type', 'application/json')
.query({id: arg[2])
.get()(function(err, res, body) {
// APIから返ってきたjsonを連想配列に変換
var json = JSON.parse(body);
//略
APIに渡すデータを get記述の前に.query()に記述する必要があるようです。
※このクエリの中身についてはXMLでもいいみたい?ですが当方このパターンしか試していません。あしからず。
DBを書き換える場合
module.exports = function(robot) {
return robot.hear(/^device index <id>$/i, function(msg) {
var arg = msg.match[0].split(/\s/);
var data = JSON.stringify({id: arg[2]}); //json型に整形
robot.http("http://localhost:8000/API/device/update")
.header('Content-Type', 'application/json')
.put(data)(function(err, res, body) {
// APIから返ってきたjsonを連想配列に整形
var json = JSON.parse(body);
//略
APIに渡すデータ .put() の引数にjson型で入れる。
まとめ
HTTPリクエストの際に使うコマンド(getとかputとか)に応じてリクエストヘッダの記述は異なります(詳しくは知りません…)。
hubot(js??)での叩き方はもちろんですが、HTTP自体の知識も最低限つけなければあかんなぁと切に感じました。
全体まとめ
こんな感じで絶賛奮闘中です。 それってQAがやることなん?と疑問に思う方もいるかも知れませんが、QAの仕事は品質を作り込むことです。 テストだけが業務ではなく、開発プロセスやサービスリリース後のプロセスにおいても作り込める品質があります。
開発中であれば「そもそもバグが仕込まれないプロセスを組むこと」もその一つ。まずマイナスを作り込まないようにすること。 テストはマイナスをゼロにする作業です。 リリース後であれば挙げ始めると切りがありません。
ざっくりとまとめると、今回の取り組みはhubotを使って今まで手間だったことを機械的に解決しようというものでした。 いろんなプロセスで「それって人の手でやることじゃないよね?」とか「開発にボール投げずに参照とか解決したいよね」とかって意外と多いんですよね。 将来どこかのプロセスで、今の奮闘をベースにその辺り解決できるちょっと便利な機能として社内で役立つといいなと思います。 しっかりとコードを書けるQAになるべく精進して行きたいと思います(という意思表明)
金型用の3Dモデリングについてのうんちくと、抜き勾配
この記事は Akerun Advent Calendar 2019 - Qiita の8日目の記事です。
最近は情報工学と3Dプリンタに興味がある、RoRエンジニアのdaikw - Qiita です。
今日は、金型用の3Dモデルを作るときには、3Dプリンタでの開発とは違う感覚が必要になる、ということの話をします。
射出成形と3Dプリンタとの違い
いわゆるものづくりでは、使用したい物質を、必要十分な精度で、目的の形状に成型する必要があります。弊社でも、その「いわゆるものづくり」を行っています。
特によく使われる素材であるプラスチックについては、昔から成型するための手法がたくさん考案されてきました。以下の二つの手法は皆さんもよく聞くのではないでしょうか。
- 金型を用いた射出成型
- 3Dプリンタによる造形(積層造形)
射出成型は古典的な手法の一つで、特に大量生産に向いていると言われます。積層造形はここ何年も盛り上がっている手法であり、個人でもプリンタが購入できるようになってからは馴染みやすいものになりました。
ここで設計者が注意すべきことがあります。それは、成型手法によって物理的な制約が全く異なるため、モデルのデザイン時にすでに成型手法のことを考慮に入れる必要がある、ということです。
私のような初心者メカジニアは3Dプリンタの方が馴染み深かったりするので、気がつくと3Dプリンタの制約に基づいてモデリングをしていたりしますが、金型に起こすためのモデルは全く違う方針をとることがあります。
3Dプリンタの制約
「積層造形」という単語からわかるかもしれませんが、3Dプリンタはモデルを高さ方向にスライスし、それを積み上げていきます。この積み上げ時に、宙ぶらりんになる部分がどうしても出てきてしまいます。
 *1
図のように、宙ぶらりんの部分はサポート材で支えてプリントすることになります。
*1
図のように、宙ぶらりんの部分はサポート材で支えてプリントすることになります。
サポート材と触れる部分は、表面状態が変わってくることがあるため、この点に注意して設計する必要があります。
精度によっては、複数の部品に分けた方がいい場合もありますし、印刷の向きを変えて対応する場合もあります(例えばT字型なら、天地をひっくり返せばサポート材はいらなくなりますね)。
金型の制約
金型による射出成型の原理は3Dプリンタよりも単純である一方で(あるいは単純であるがゆえに)、制約は3Dプリンタより複雑です。
金型は、キャビティとコアと呼ばれる二つの金型をセットにして用います。*2

さらに射出成型のプロセスを分解すると、 *3
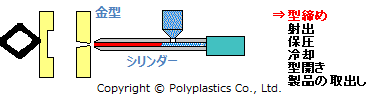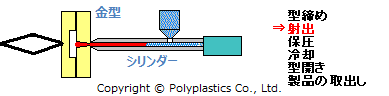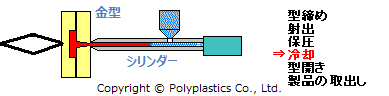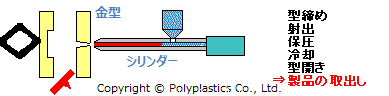
これを単純化すると、『「二つの金型の間に、熱して溶かしたプラスチックを注入し、冷まして固化させて、取り出す」を繰り返す』必要があります。 これらの工程ごとに、金型への制約を考えることができ、
二つの金型の間に樹脂を流すことから、
- 部品の一方の面はキャビティに触れていて、反対の面はコアに触れている
- 金型の分離面(parting-line)が存在して、これが部品に触れている
熱して溶かしたプラスチックを注入することから、
- 溶融プラスチックが隅々まで綺麗に流れる形状である(流路が複雑すぎない)
冷まして固化させることから、
- なるべく全体が均一な厚みである(一部だけが厚いと、離型前に冷えきらず、離型後に冷えて凹んでしまう)
取り出すことから、
- 金型から十分に剥がれやすい(離型性)
金型用3Dモデルの設計時に気をつけるべきこと
制約について見てきましたが、金型用の3Dモデリングで3Dプリンタと違って気をつけるべきことを大雑把にまとめると、
- parting-lineの存在
- 均一な厚み
- 離型性
特に離型性は、二つの性質に分ける事ができて、
- そもそも剥がれうる形状である ~= 横方向の凸・凹形状(アンダーカット)がない
- 剥がれやすい形状である ~= 抜き勾配が十分にある
となります。
抜き勾配の付け方
弊社では、3D-CADソフトはFusion360を使っています。こやつは無料でも使用できるのに高機能であり、プロジェクトやファイルの共有もクラウド管理できる、便利なやつです。
最近Generative Designで何かと話題ですが、残念ながら弊社ではそんなキラキラした機能は使っていません()。
さて、Fusionには抜き勾配(draft)機能は存在します。が、あまり便利ではありません。。。
これは何故かというと、
- 絶対値で指定できない(元あった面からの相対的な傾きになる)
- parting-lineとしての指定ができない(基準面はある *4
- 他のFeatureと衝突しやすい
ためです。
任意のdraftをつけるためには、自前で平面を作るしかなく、Fusion360の不便な点ではあります。 forums.autodesk.com
他の3D-CADだったら?
ハイエンド(数百万円くらい)の3D-CADはもちろん複雑な抜き勾配featureが用意されていますし、他にも意味のわからない機能が大量に付いています。
- 2017 SOLIDWORKS ヘルプ - 抜き勾配(Drafts)
- Creating Drafts with Parting Elements | CATIADOC
- 金型設計と鋳造 > モールドおよび鋳造フィーチャーの作成 > ドラフトカーブと分離カーブ > ドラフト環境を定義するには | Creo Parametric 5.0.5.0 オンラインヘルプ
同じような価格帯の3D-CADの中でも、OnShapeはparting-line指定ができるようになっています。
最後に
自分の勉強がてら、金型と樹脂成形についてまとめました。
大量生産の手法はそれ自体が興味深く、プロダクトの設計・開発とはまた違った楽しみがあるなと感じました。
今は、10万円程度で金型に起こしてくれるサービス*5も出てきています。お試しあれ。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 hrmos.co
Akerun Proの購入はこちらから akerun.com
地磁気で屋内測位をやってみた(サービスとして使えるようにしたとは言っていない)
この記事はAkerun Advent Calendar 7日目の記事です。
こんにちわ、はじめまして、11月にフォトシンスに入社した nbs です。 Webシステムの開発を担当しております。まだ、入社したばかりですが、ゆくゆくは機械学習を用いた新サービスとか作りたいです。
Akerunは入退室が正確に管理できるサービスですので、入室しているのか、退室しているのかをきっちり、かっきり確認できます。
ただ、室内のどこにいるのかが知りたい場合もありますよねということで、 本アドベントカレンダーではスマホアプリでの 屋内測位 にチャレンジしたいと考えています。
特別な端末を必要とせず、スマホで人の屋内の位置がわかったら素敵やん。
ということで、後で理由は記載しますが、採用した手法は地磁気での屋内測位です。地磁気のデータを元に位置情報をベイズ推定したのですが、精度がでなかったため、 逐次モンテカルロ法 を用いて精度向上を図りました。
目次:
思ったよりも長い記事になってしまったので、先結(=先に結論を書きましょうの略)でいきます。それなりの結果になりました!
- 精度は頑張ればそれなりに出る(概ね1m)
- 導入時は費用と時間はそれなりにかかる
- 精度を出すためにアプリを起動し続ける必要がある
- 精度を出すために使用者ごとの学習が必要(涙目)
- 基準点があると更に良い感じになる
地磁気測位、君に決めた!
屋内測位の手法はかなりの数があります、詳しく知りたい方はGoogleで検索していただくと、色々な比較記事風の広告が出てくると思います。
今回、地磁気測位を選んだ理由として以下2点を上げさせていただきます。
- 他方式に比べて、特別なデバイスが不要であること
- 記事にした際に、そこそこ盛り上がる精度は出るのではないかという期待感(PDR: 歩行者自立航法測位も興味あるが、精度出すのシンドイ)
注)駅や倉庫の屋内測位で地磁気測位を用いようとした際に、鉄道車両や大型車両が近くを運行すると地磁気が乱れるという弱点があります、そのため、駅や物流拠点の測位には向きません。他の測位手法にもそれぞれ弱点がありますので、実際に導入する際には、しっかりとした検討をお勧めします。
iPhoneと地磁気と回転と
地磁気(ちじき、英: geomagnetism、Earth's magnetic field)は、地球が持つ磁性(磁気)である。及び、地磁気は、地球により生じる磁場(磁界)である。磁場は、空間の各点で向きと大きさを持つ物理量(ベクトル場)である。
そう、地磁気とは地球の磁場です。地磁気測位は、磁場をセンシングしてるんですね。磁場って、建物の鉄骨に影響うけるんです。詳しくは参考サイトをご覧ください。簡単にいうと、 磁場によって、微量ですが鉄骨が磁化し、その磁化した鉄骨で磁場が発生するっていう。電場と同じ現象が起こっています。ちなみに先述の電車やトラックが近くを通ると磁場が乱れる理由もわかりやすく解説されています。
参考サイト:地磁気観測所|基礎知識|Q&A
さて、地磁気による屋内測位いけるやんと思った方。 そもそも、iPhoneに、何故、地磁気センサが搭載されているのでしょうか。 そう、iPhoneの向きを把握するためですね。iPhoneの向きが変わると、センサの値が変わります。
おっと、全く回転させずに歩いて移動できるのかと思った方。 正解です、無理です。意識して歩いても無理。 ではどうするのかということですが、 1つの方法は、ジャイロセンサからどう回転しているのかを計算して、そこから地磁気を計算するという方法。 今回やってないですが、恐らく、こちらでも頑張れば何とかなるでしょう。
ただ、今回はお手軽に実装したいと考えたので、iPhone側の機能に依存しようと思います。
さて、iPhoneで取得可能な地磁気の値に3つの種類があるのはご存知でしょうか。
上記サイトの引用の訳ですが
地磁気のデータに関して、iOS側で様々な処理をかけていることがわかります。2はiPhone内部の磁場の影響の除去、3の局所的な外部磁場というのに、建物の鉄骨による影響の除去も含まれますね。2と3の差って、局所的な外部磁場の影響の除外ですから、この差って、回転によらないはずですよね。
地磁気測位をするために、BLE端末を買った orz
屋内測位で地磁気を用いる方式を簡単に説明しますと、
こうやって、書くとめっちゃ簡単! ですが、実際には、最初に位置と地磁気を正確に紐づけることがとてもとても重要です。それを怠ると、そもそも望んでいる結果が得られません。
簡単に位置を正確に測位するという方法を考えると、BLEビーコン測位が頭に浮かびました。
地磁気による屋内測位のための地磁気マップを作成するために、BLEビーコン測位を行う。訳がわからないよ、初めからBLE測位で良いじゃんと思った方、私も一瞬そう思いました。ですが、これは最初だけの苦しみなのです。 私が正確な地磁気マップを作成すれば、後続の方が使うときにはBLE端末を取り除いても良いのです。
つまり、最初、地磁気マップを作るのにBLE端末がいるが、その後、そのBLE端末は別の場所の地磁気マップを作るのにも使えるということですね。買いきりしてもらう必要はなく、導入時に貸し出すだけで良い。お金の匂いがしてきましたね!
前置きが長い、コードを寄越せ
ええ、私もそう思います。ですが、コードがすっごい長くなったので、気が向いたらGitで公開します。
以下、抜粋
var trackingCLLocationManager:CLLocationManager!
var beaconRegion:CLBeaconRegion!
var cmManager:CMMotionManager!
// 設置したビーコンのUUID。iOSで検出可能な上限数は20個程度のため、
// 測位エリアをいくつかに分割し、計測を起こっていく必要がある
let UUIDList = [...]
override func viewDidLoad() {
super.viewDidLoad()
// 表示部分の処理、省略
// ロケーションマネージャを作成し、delegateを自身に設定
trackingCLLocationManager = CLLocationManager()
trackingCLLocationManager.delegate = self
// 取得設定の初期化(精度最大、頻度設定1mごと)
trackingCLLocationManager.desiredAccuracy = kCLLocationAccuracyBest
trackingCLLocationManager.distanceFilter = 1
// セキュリティ認証のステータスを取得
let status = CLLocationManager.authorizationStatus()
// まだ認証が得られていない場合は、認証ダイアログを表示
if(status == CLAuthorizationStatus.notDetermined) {
trackLocationManager.requestWhenInUseAuthorization()
}
// CLLocationManagerの地磁気測位開始
trackingCLLocationManager.startUpdatingHeading()
}
/*
iBeaconの検出を開始する.
*/
private func startMonitoring() {
// UUIDListから対象設定
for i in 0 ..< UUIDList.count {
// BeaconのUUIDを設定.
let uuid: NSUUID! = NSUUID(uuidString: "\(UUIDList[i].lowercased())")
let identifierStr: String = "ps_\(i)"
// リージョンを作成.
beaconRegion = CLBeaconRegion(proximityUUID: uuid as UUID, identifier: identifierStr)
// リージョンへの入場, 退場通知の設定.debug時はtrueオススメ
beaconRegion.notifyOnEntry = false
beaconRegion.notifyOnExit = false
// モニタリング開始
trackingCLLocationManager.startMonitoring(for: beaconRegion)
}
}
/*
認証ダイアログで許可された場合、モニタリングを開始、拒否された場合、何もしない
*/
func locationManager(_ manager: CLLocationManager, didChangeAuthorization status: CLAuthorizationStatus) {
switch (status) {
case .authorizedAlways:
startMonitoring()
case .authorizedWhenInUse:
startMonitoring()
}
}
/*
モニタリング開始時にリージョンに入っているか確認する
リージョンに入った出たの変化をイベントとして感知するので、モニタリング開始時の状態を確認する必要がある
*/
func locationManager(_ manager: CLLocationManager, didStartMonitoringFor region: CLRegion) {
// リージョン内かどうかの確認
manager.requestState(for: region);
}
/*
リージョン内にiBeaconが存在するかどうか
*/
func locationManager(_ manager: CLLocationManager, didDetermineState state: CLRegionState, for region: CLRegion) {
switch (state) {
case .inside:
// リージョン内にiBeaconが存在いるのでRangingを開始
// 他のステータスでは何もしない
manager.startRangingBeacons(in: region as! CLBeaconRegion)
}
}
/*
現在取得しているiBeacon情報一覧を取得、処理
*/
func locationManager(_ manager: CLLocationManager, didRangeBeacons beacons: [CLBeacon], in region: CLBeaconRegion) {
if(beacons.count > 0){
// 位置計算に回す分のビーコンの連想配列
var targetBeacons: [String: Double] = [:]
for_beacon: for i in 0 ..< beacons.count {
let beacon = beacons[i]
// Proximity unknowのデータは使用しない
switch (beacon.proximity) {
case CLProximity.unknown :
continue for_beacon
}
// 距離計算
let distanse = pow(10.0, (beacon.power - beacon.rssi) / 20.0)
targetBeacons[beacon.uuid] = distanse
}
// targetBeaconsの要素数に応じて、位置計算処理に回す
// 位置計算処理は省略
// 地磁気の取得
}
}
/*
ビーコン検出時、Ranging開始
*/
func locationManager(_ manager: CLLocationManager, didEnterRegion region: CLRegion) {
manager.startRangingBeacons(in: region as! CLBeaconRegion)
}
/*
ビーコンを見失って時間が経ったとき、Ranging停止
*/
func locationManager(_ manager: CLLocationManager, didExitRegion region: CLRegion) {
manager.stopRangingBeacons(in: region as! CLBeaconRegion)
}
/*
地磁気の角度更新時
*/
func locationManager(_ manager: CLLocationManager, didUpdateHeading newHeading: CLHeading) {
// 今回はビーコン検出をトリガーとして、組み合わせデータを作成した
print(-newHeading.magneticHeading)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
}
上記のように、ビーコン側の検知をトリガーに地磁気を取得して、ビーコン側から計算できる位置と地磁気の差分を記録しました。
地磁気マップを保持して、ベイズ推定をしたのですが、この時点でそこそこ精度が出ていました。ですが、ときたま、大きく位置がずれることがありました。
ふと気づいたのですが、地磁気の値はユニークとは限らないんですよね。 (x, y) => (gx, gy, gz) を記録して、逆引きした際、(gx, gy, gz) => (x1, y1) or (x2, y2)になることもあるわけです。
そこで考えました。精度を上げるために、逐次モンテカルロ法を用いようと。
逐次モンテカルロ法を使おう、ただし、時系列ではない
さて、逐次モンテカルロ法、知ってる人は知っているし、知らない人は知らないですよね。詳細はGoogle先生にお願いするとして、簡単に説明します。 当初、用いていたベイズ推定は、ある特定の状態のみを切り取って値を推定するのに対して、逐次モンテカルロ法は、連続する状態の推定を過去の観測データも用いながら推定します。
ちょっぴり内容が難しくなってきましたね。なんで、そんなことをしたいのかというと、実際に人が動くときは、連続した状態で変化をしていきますよね。入り口にいた人が急に反対の壁に瞬間移動することはなく、入り口から、徐々に反対の壁まで移動していき、その状態も観測できる訳です。今回でいうと、観測するのは地磁気ですから、入り口の地磁気から、内側の地磁気、反対の壁の地磁気と観測されるのが正しい訳です。現状態から起こりえない突然の事象を除外できるっていうことですね。
元々は、[A - Z]のどの地点にいるかを地磁気から推定していたわけですが、元々Aにいたとしたら、全ての地点に行ける訳ではなくBに行くか、Cに行くか、Aに留まるかしかないとイメージしてみてください。その状況なら地磁気の観測値からAにいるのかBにいるのかCにいるのかを推定すれば良い訳です。分かりやすいように具体例をあげたはずなのに、分かりづらくなるとはこれいかに。わからなかったよっていう人はお父さんに聞いてみてください。きっと困ると思います。
さて、ここで問題なのが、よくあるパターンだと、状態の推移に関して、時間軸でどう変化するのかを用います、時系列データですね。ですが、実際の人の動きの場合、停止もある訳です。オフィスなんかだと、長時間座りっぱもありますよね。私もよくその状態にあります。
今回は、移動の歩数による連続状態を考えてみました。iPhoneだと歩数が簡単に取得できます。歩数ごとの地磁気の変化から歩数ごとの位置の変化を推定したわけです。
逐次モンテカルロ法の辺り、Swiftで実装してもよかったのですが、ありものを使おうと言うことで、逐次モンテカルロ法を用いた推定部分はサーバサイドのPythonで行いました。そのため、全てのコードを載せるのもしんどく少し地磁気を観測してから位置を推定されるまで、時間差があります。約4秒ほどね。
実際にサービスとして提供するためには、エッジ側での処理を検討した方が良さそうですね。
まとめ
先に書いた通り、個人的にはそれなりの結果だなと思います。勉強になることも多く、精度も当初予定通りに強引に納めたので満足です。ただ、即サービス化するのは色々難しいですし。割とハードル高いですね。
精度は頑張ればそれなりに出る(概ね1m) → これ以上の精度を求めるには、地磁気マップ作成時の位置測位をより正確に行える方法が必要。
導入時は費用と時間はそれなりにかかる → iBeaconを20個買って、4,000円くらいでした。後ほど、これらiBeaconはスタッフが別用途で美味しく食べました(使いました)。また、地磁気マップ作成に思ったより時間がかかりました。今回、自分の家で試してオフィスにトライする予定だったのですが、観測エリアの広さに、地磁気マップの作成、学習にかかる時間が比例するとすると、20日以上かかることになりますね。(自宅で地磁気マップ作成に4日も要しました)
精度を出すためにアプリを起動し続ける必要がある → 逐次モンテカルロ法を用いて精度を上げたので、連続したデータが必要でございます。
精度を出すために使用者ごとの学習が必要(涙目) → 逐次モンテカルロ法における状態の推移を歩数軸にしたので、個人差が出ますね。ただ、自分で実験した限り、時間より歩数の方が安定して推定できました。
基準点があると更に良い感じになる → 実は、今回の記事の出発点は、基準点にAkerunって最適じゃないかしら?!です。大真面目に、NFCで扉を開けるときは位置が決まっていて、ほぼ速度0ですから基準点としては最適ですね。もうちょい導入時のハードルが低かったら嬉々として提案したのに。。
また、先に書かなかったところですと、オフィスでの利用を考えた場合、地磁気測位では垂直方向が推定できないので、今、どこの階にいるのかを別の方法で推定する必要があります。フロアの区切りが階によって異なる場合(多くの場合そうだと思いますが)どの階にいるかわからないと、逐次モンテカルロ法によって、余計誤差が出るようになりますね(笑)
時間があれば、加速度センサから今何階か判別したかったのですが、階段で上がった場合の加速度の波形を見て今回は諦めました。ちなみにエレベーターで上昇するパターンは、事前学習は当然必要ですが、どうにかなりそうです。
ということで、引き続き、開発していきたいと思います。機会があれば、第2弾ということで。ニーズの範囲にコストを納めるのって、本当に大変。
・・・
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 hrmos.co
Akerun Proの購入はこちらから akerun.com
みんなで使える組み込み開発環境 Zephyr RTOS編
この記事はAkerun Advent Calendar 6日目の記事です。
はじめまして、2月にフォトシンスに入社した いとう です。 Akerun入退室管理システムの中のハードウェアを動作させるファームウェアという奴をぼちぼち開発しています。
IoT機器を開発しているフォトシンスでは Zephyr RTOS をやっていこう!という話になり、今回はその開発環境構築の取り組みについて書いてみようと思います。あんまりZephyr本体の話は出てきません。
TL;DR
- 開発環境はコンテナだよ
- GitLabでDockerfile管理してGitLab CIでイメージ生成してGitLab Container Registry でイメージ管理するよ
- VSCode の Remote Development 使えばシャッキリポン
組み込みファームウェアの開発環境について
所感ですが、これまでのファームウェアエンジニアは開発環境について良くも悪くもあまり頭を悩ませずにきたと思います。なぜなら採用したマイコン・SoCベンダーからIDE一式が提供(推奨)され、それをサンプルコードそのまま使うケースがほとんどだからです(観測範囲狭し)。まあ、開発環境を作りたいのではなく製品を作りたいので当たり前といえば当たり前ですが・・・。
これまではそれでよかったのかもしれません。IDEのビルドボタンをポチッと押してビルドして、書き込みできれば仕事はできます。しかし、せっかく環境を一新するのであればこれまであった不満を解消したいじゃないですか。
- 不満① Git管理に向いていない
どこのIDEも同じですがIDEのプロジェクトファイル、Gitで管理しにくいですよね?プロジェクトファイル開いてビルドして閉じただけで差分が出てしまうしデバッガ使っただけで差分が出ます。明らかにプロジェクトファイルに変更がなければコミットしなければいいんですが、ファイルを追加したりインクルードディレクトリ追加したりしたらコミットせざるをえません。自動生成されるファイル類もGitで管理対象とすべきかどうか明文化されていないし。
- 不満② 環境構築に時間がかかる
今はPrallels Desktopで環境構築しているので最初にセットアップすればイメージファイルを移動させるだけで良いのですが、前職ではPCリプレイスするたびに丸1日以上かけて環境を構築していました。ARM純正のコンパイラ入れて、それにパッチ当てて、ライセンス設定して・・・
- 不満③ 気軽に開発体験できない
そして、個人的な1番の不満はこれです。弊社、最近エンジニアが増えてきていて、中にはウェブエンジニアが垣根を超えて組み込み開発やってみたいっていう危篤奇特な人達が何人かいるんですけど、みんな macOS なんですよね。Akerunのファームウェアをいじって遊べれば楽しいと思うんですが、Windowsでしか動作しないIDEやコンパイラ・・・気軽に体験してもらえないんです。
方針
Zephyr RTOS のガイド を見ればわかる通り Zephyr RTOS では Ubuntu, macOS, Windowsがサポートされていてセットアップ方法も懇切丁寧に記載されてます。つまりWindows縛りはありません。しかも cmake + ninja をベースとしたIDEレスな開発環境です。ただ、やはりあれこれとインストールしなければならないのは変わりませんので、これを解決するために開発環境をDockerコンテナで構築することにします。
開発環境をコンテナで
開発環境をDockerコンテナで構築するというのは今となっては珍しい話ではありませんね。Zephyr RTOSでは本家がCI用で使っているDockerfileをGitHubで公開していますし有志の方が公開しているDockerfileもあります。これを使えばいいのですがそのほかに必要なツール類も一括管理するために独自でDockerfileを作成しました。
FROM ubuntu:18.04 ARG SDK_VERSION=0.10.3 ENV ZEPHYR_SDK_SETUP zephyr-sdk-$SDK_VERSION-setup.run ENV ZEPHYR_TOOLCHAIN_VARIANT zephyr ENV ZEPHYR_SDK_INSTALL_DIR /opt/zephyr-sdk ENV PROJECT_DIR /hogehoge RUN apt-get update RUN DEBIAN_FRONTEND=noninteractive apt-get -y upgrade RUN DEBIAN_FRONTEND=noninteractive apt-get install -y git cmake ninja-build gperf \ ccache dfu-util device-tree-compiler wget \ python3-pip python3-setuptools python3-tk python3-wheel xz-utils file \ make gcc gcc-multilib \ locales \ clang-format RUN pip3 install cmake west requests docopt RUN cd /tmp && wget https://github.com/zephyrproject-rtos/sdk-ng/releases/download/v${SDK_VERSION}/${ZEPHYR_SDK_SETUP} RUN chmod 755 /tmp/${ZEPHYR_SDK_SETUP} RUN /tmp/${ZEPHYR_SDK_SETUP} -- -d ${ZEPHYR_SDK_INSTALL_DIR} RUN apt-get clean && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* RUN locale-gen en_US.UTF-8 ENV LANG en_US.UTF-8 ENV LANGUAGE en_US:en ENV LC_ALL en_US.UTF-8 ## 中略 〜秘密〜 中略 WORKDIR $PROJECT_DIR ENTRYPOINT ["/bin/bash", "-c"] CMD [ "/bin/bash", "-c" ]
今見返したらほぼ参考にした marshall/zephyr-docker と同じでした。実はここからUbuntuベースではなくAlpine Linuxベースに変更しようとしたのですがパッケージマネージャから必要なツールが入手できずに断念した結果です(確かdevice-tree-copiler)。Zephyrはお好きなコンパイラ選べるんですが本家がリリースしているSDKを採用しています。(Locale設定しているのはなんでだっけ?)
イメージ生成、配布は GitLabで
さて、Dockerfileができたので皆にこれを使ってもらえばいいのですがまだ問題があります。それはapt-get、pipなどのパッケージマネージャで取得したパッケージが更新されるとイメージを作る時期によって生成されるイメージが変わってしまい、さらにはパッケージレジストリのメンテが終了するとイメージ自体の生成に失敗してしまいます。この対策としてDockerイメージ生成して、それを共有することにしました。DockerイメージのレジストリはDocker Hubが有名ですが、ちょうど社内に導入した GitLab に Container Registry機能があったため、こちらを使用することとしました。
GitLabはCIが内蔵されており(最近GitHubでもできるようになりましたね)ブランチやタグのpushなどと連動して、GitLab Runnerを走らせているマシンで任意の処理を実行させることができます。試しに開発環境用Dockerfileのプロジェクトファイルのルートに .gitlab-ci.yml という名称のファイルを作り↓の内容記載してGitLabにプッシュすると、Dockerビルド〜GitLabにDockerイメージをプッシュするところまでできてしまいました。
stages: - build - test - deploy variables: IMAGE_BRUNCH: $CI_REGISTRY_IMAGE:$CI_COMMIT_REF_SLUG IMAGE_TAG: $CI_REGISTRY_IMAGE:$CI_BUILD_TAG before_script: - docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY build: stage: build script: - docker build -t $IMAGE_BRUNCH . - docker push $IMAGE_BRUNCH tags: - build-docker tag-build: stage: build only: - tags - triggers script: - docker build -t $IMAGE_TAG . - docker push $IMAGE_TAG tags: - build-docker
たったこれだけで下記のように GitLab にイメージが格納されプロジェクトのメンバーであれば誰でもイメージが取得できるようになりました。しかもGit側でタグ打てば連動して Container Registry上でもタグが打たれてタグでバージョン管理ができます。

上記のイメージを引っ張ってきつつdocker runするには↓
docker run --name saituyo-env -it -v ~/host_no_repo/zephyr:/hogehoge odorenotokorono.gitlabnourl.com:5555/hogehoge/dev-env-docker:0.1.1
これでいつでも誰でも使える開発環境+再現可能な開発環境ができました!めでたしめでたし。
一歩進んで VS Code Remote Development
さて、めでたしめでたしなんですが、"みんなで使える"とうたった割には Docker自体の知識が少し必要だったり敷居が高いことは否めません。実際に自分で使ってみて課題も出てきました。
- Dockerの使い方を勉強する必要がある(メンテ用コマンドとか)
- 特定のブランチ、タグがどのバージョンの開発環境に対応しているのか不明
- コンテナ生成初回におまじないがある
- これはZephyr固有の問題ですがセットアップ時にあれだけ色々インストールしているのに、ビルドするためには追加のpythonのパッケージが必要となります。しかもこの必要パッケージのリストはZephyrのソースコードの中にあるため、どうしても開発環境コンテナの中には組込めませんでした。
- あと各種の環境変数をセットアップするのにやはりソースコード内のスクリプトを実行する必要がありこれも開発環境コンテナの中には組込めませんでした。
どうしたか?
世の中便利になったもので VSCode にはDockerコンテナの中でプロジェクトを編集できる VSCode Remote Development 機能拡張があります。この機能拡張をインストールしたVSCodeでプロジェクト直下に.devcontainer/devcontainer.jsonを配置していると記載した設定にしたがってプロジェクト全体をDockerコンテナ上でマウントした状態で立ち上げてくれます。そしてdevcontainer.jsonに下記のように記載すると、なんと!自動的にイメージをGitLabから取ってきて、さらには Pythonの必要パッケージのインストール、環境変数のセットアップまでやってくれます。
{ "name": "hogehoge firmware", "image": "odorenotokorono.gitlabnourl.com:5555/hogehoge/dev-env-docker:0.1.1", "extensions": [ "ms-vscode.cpptools", "EditorConfig.EditorConfig", "plorefice.devicetree", "twxs.cmake", "eamodio.gitlens", ], "runArgs": [ "-v", "${env:HOME}${env:USERPROFILE}/.ssh:/root/.ssh-localhost:ro" ], "postCreateCommand": "pip3 install -r zephyr/scripts/requirements.txt && echo 'source ./zephyr/zephyr-env.sh' >> ~/.bashrc && mkdir -p ~/.ssh && cp -r ~/.ssh-localhost/* ~/.ssh && chmod 700 ~/.ssh && chmod 600 ~/.ssh/*" }
(sshをごにょごにょしているのはコンテナ内でもホスト環境のssh鍵を継承してgitにアクセスするためです)
そして、この.devcontainer自体もgit管理プロジェクトとして組み込んでしまえば特定バージョンのソースコードに連動した開発環境をVSCodeが自動的に引っ張ってきてくれるようになります。実際はソースコードのリポジトリに.devcontainerをコミットしたわけでなく独立したGitLabのプロジェクトとして存在して、Zephyr (west) の複数Gitリポジトリ管理機能でファームウェアソースコードリポジトリと同期させてます。
これでVSCodeを使う限りDockerの知識がなくてもソースコードのディレクトリを開くだけで追加おまじない不要なビルド環境が付いてくる、"みんなで使える"開発環境が用意できました!ただ、開発環境をVSCodeで完全に縛ってしまうと夜道でVimmerにさっくりやられてしまう世知辛い世の中ですので、純Dockerで使える環境はキープするのが全体的に幸せと思われます。
まとめると
- 各自の環境にインストールすのは
git / python3 / west / VSCode / Dockerだけ west initでリポジトリ取ってきてVSCodeで開き、おもむろにTerminalでwest build hogehogeとするともうファームウェアが出来ちゃう
という個人的には理想に近い環境が出来上がりました!あとはこの環境でみんなで開発を進めていくだけです。
オチ
回路エンジニア(Windows)の方が環境構築に挑戦したところ、実はWindows HomeではHyper-Vなしのため、VSCode Remote Developmentが使えないことが判明し即刻挫折しました 😩!ケチケチするなよMicr◯s◯ft!Windows 10 Pro ならいけるんじゃないでしょうか?知らんけど。
おわり
・・・
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 hrmos.co
Akerun Proの購入はこちらから akerun.com
IoT企業ではたらくエンジニアに知ってほしい 組み込みエンジニアの生態系
これはAkerun Advent Calendar5日目の記事です。
はじめに
Photosynthという会社は Akerun という入退室管理システムを提供しています。 ハードウェアからクラウドまで一気通貫で自社開発している、スタートアップでは数少ない会社のひとつです。
書いてる人
Akerunの中の人です。元は大手電機メーカーで組み込みやってました。Photosynthにジョインしてからは ファームウェアやったりアーキテクトしたりいろいろやってます。
この記事

※個人の主観です。
私がWebエンジニアたちと一緒にプロダクト開発をしてみて感じたギャップに基づき、組み込みエンジニアの特異な性質について書いてみました。
共感する部分があれば、ふふっと鼻で笑ってやってください。
プログラミング・設計編
状態を持たせる設計をする
組み込み屋さんは状態をもたせる設計を好みます。
A) Hogeの状態でメソッドを実行するとFugaする B) hogeHogeの状態で同じメソッドを実行すると無視する
など、状態によって処理を分岐します。ちゃんと理由があります。これはハードウェアは基本的に状態を持っていることに起因します。わかりやすい例だと、電源がONかOFFかが状態。ONのときは処理するがOFFのときは無視されますね。
一方でwebAPIを設計するときはリクエストに対して常に一定のレスポンスを返すことを期待する設計をとることが多いと思います。
お互いの思想を尊重した設計をとる必要があります。
ステートマシン大好き
状態を多用するので、ステートマシンを実装することが非常に多いです。100%です(自分調べ
UMLをみんな読み書きできると思ってる
設計はシーケンス図とクラス図(モジュール構成図)、ステートマシン図から始まります。シーケンス書かないとか設計じゃな
駆け出しの頃はIT専科さんにはお世話になりました。
数値の上限をとても気にする
変数には必ずサイズがあるので特に上限値を気にします。値が128や256に達するかとか、とても重要です。 連番で発行するidの上限でよく喧嘩します。
負値になりえるのか気にする
符号なし変数を多用するので、実装後に急に負の値が仕様に出てくるとキレます。切実です。
符号なし変数を使う理由は、同じサイズで上限が大きくなるからです。
符号あり1Byte: -128〜127 符号なし1Byte: 0〜255
理由がなければ符号なしを使います。
小数がでてくると青ざめる
リソースがプアなマイコンでは特に小数を扱えません。
実際には、整数部分と小数部分を別変数で定義する実装で対応したり。
わかりやすさよりもリソースを優先しなくてはならない(したい)
以下にもうすこし細分化します
1バイトに複数のパラメータを突っ込む
1Byteの中で、1bitずつ(もしくは複数bitまとめて)意味をもたせます。
フラグなど、booleanなら最大8つ入ります。
例えば
成功失敗:boolean 結果:0-100までの値
を格納したい場合、
| offset | size | param |
|---|---|---|
| 0 | 1bit | 成功 |
| 1bit | 7bit | 結果 |
というルールを決めて1Byteに入れてしまいます。理由はサイズを小さくするためです。 少ないメモリで処理したい場合や、通信で流れるサイズを小さくしたい場合に多用します。
パラメータのやり取りを文字でやらない
理由は主にサイズです。
文字(string)型はサイズが大きいのです。1文字あたり1Byteも必要です。しかも{}や""なども文字です。そして文字列の最後は塗る終端\0が入るのでこれも1バ(ry
たとえば
成功:boolean 結果:0-100までの値
というパラメータ群を送りたい場合、
JSON:{"success":true,"result":100} で30Byte必要ですが、先程でてきた
| offset | size | param |
|---|---|---|
| 0 | 1bit | 成功 |
| 1bit | 7bit | 結果 |
というルールを決めれば1Byteに入ってしまうのです。
パースについては、近年便利なライブラリが出てきたのであまり気にしなくて良くなってきました。
相手が論理演算できることを期待する
上記の理由から、やりとりする相手に論理演算を要求します。
上で示した1Byteの値から値をパースするには
success = a & 0x01 result = (a & 0x0e) >> 1
という実装してね?と web屋さんに要求します。悪気はないです。
掛け算・割り算をビットシフトでやりがち
hoge * 2 : `hoge << 1` hoge / 4 : `hoge >> 2`
理由は演算スピードと、あとは好みです。
nilなんてない
レガシーな組み込みの世界では NULLと0が同値です。 なので未定義であることを示す値をあえて定義します。変数の上限値0xff(255)を使うことが多いです。
#define NIL (0xff) if (a == NIL) { // エラー処理 }
マイコンやフラッシュメモリでも、未使用のメモリ領域は0xffが書かれていることが多いです。
型がないと不安
型がない言語は気持ち悪いですね(個人の感想です
変数がメモリにマップされるかわからないと落ち着かない
ほんとにメモリ確保されてるのか、生存期間とかが明確じゃないと怖くて使えません。
確率的におこるバグと闘う
組み込みでは、確率的に起こるバグがあるので、数万オーダーのテスト(エイジングやヒートランと呼びます)を回します。 Webではあまりないんですってね。
言語編
石
マイコンやSoCのことを石と呼びます。石ころで遊んでるわけではないです。
治具
治具という言葉はとても広義ですが、石にプログラムを書き込む器具を治具と読んだりします。
API
APIというと、構成モジュール間の呼び出しIFを指します。
curlで叩くアレをカジュアルにAPIと呼ぶことに慣れるのに時間がかかりました。
16進数をしゃべる
イチエフ(1f) とか サンナナ(37) といった表現を使います。16進数です。
あ、デバッグダンプは16進数で出してあげてください。
16進数から2進数を暗算する
16進数をみると2進数がすぐにわかります。変態だからではありません。1Byteに複数のパラメータが含まれることがあるので、値を知るには2進数表記を知る必要があるからです。どのbitが立っているかわかる、とも表現します。気持ち悪いとか言わないでください。
バイナリを読む
組み込みの世界ではコンパイラによって処理が意図しなくなってしまったりすることがあります。差分を見るために、ビルドしてできたバイナリを直接比較したり読んだりすることがあります。気持ち悪いとか言わないでください。
弱点編
静電気に弱い
ハードウェアを扱うので静電気に敏感です。開発機が死んで途方にくれます。割とあります。ピカチュウ。
乾燥に弱い
以下同文
EOLに弱い
ベンダーロックインせざるを得ないこともあるのですが、SoCが変わると死にます。
webエンジニアと働いてみて
めちゃめちゃ楽しい ✌('ω'✌ )三✌('ω')✌三( ✌'ω')✌
おわり
他にもたくさんありますが、このくらいにしておきます。 最近はIoTもすっかり当たり前化してきているので、組み込みエンジニアと仕事をする機会も多いと思います。 これを読んで「組み込みの人って16進でしゃべるんでしょ?」など話題をつくってもらえたら嬉しいです。
一緒にプロダクト開発するエンジニア募集してます!
QA初心者がQAゼロの企業に入ってみたら
はじめまして、Photosynth初のQAの人です。
AdventCalendarに何か書けと言われたので、「何を書こうかなー?」と悩んだのですが 丁度良かったので、自分のポジションであるPhotosynthのQAの話します。
注意:エモいです。書いてて吐きそうになりました。
(この話は、自分でその時感じていたことを記録していたメモを掘り起こして書きます。)
始まり
紆余曲折あって2019年3月転職しました。
第三者検証会社から転職した先は
QAチームもテストチームもテストの知識があるメンバーもいない会社でした。
そこからQA初心者がQAとしてのキャリアを始めることになりました。
それまでの理解
自分と会社のQAエンジニアというものの認識を整理します。
自分:
QAって、テストだけじゃなくて経営レベルでプロダクトのことを考えているんだよなー
ユーザにいかに価値を提供するか、提供し続けるかを考える人なんだろうなー
詳しくはよくわからんけど。
開発メンバー:
QA=テストのことでしょ?
「QAお願いしまーす」っていうとテストしてくれる人が入ってくる!
開発楽になるわー
会社:
わからんけど、QAってテスト専属ポジションの人が入ったらしい。
見えてきた問題点
1ヶ月経った時点で、案件の大小はあれどいくつかの案件をこなしました。 テスト実施だけだったり、テスト設計からきちんとやってみたり、開発者に指示をしてみたり……
そんなことをしていると、違和感というか、何か変な感じがしていました。 「この辺が問題点なのかも」と思ってその当時メモしてたみたいです。
- テストスコープが不明確 - 影響範囲の考慮不足 - 仕様の複雑化を許容する体制 - テスト技術の知識不足 - テストの実行依頼をする側、される側のコミュニケーションロス - リリース判定の曖昧さ etc…
そもそも、上流から案件に関わってないし、品質をチェックするだけで作り込めてないのでは?
今このポジションは、ただのテスト作業には変わりないのでは?
当時のメモ
問題の解決に向けて、まず1人では解決できないorできても時間がかかり過ぎると考えて、周りの人々を巻き込むことにした。 「(仕様について記載されているドキュメントは)QA仕様書(テストケースのこと)しかありません。」 この一言に対して様々なことを投げかけたくなるが、とにかくドキュメントがないならばしかたがない。 過去のテストケースを漁っていくことにした。
改善へ向けて
その後やったこと
- QAってなんなの?を身近な人に話してみる(反応を見てみる) - QAってなんなの?を自分で勉強してみる(社外勉強会とか) - テストってなんなの?を調べてみる(QAとテストって別物?の認識確認) - 開発者との対話を増やして、お互いの認識を確認し合う(誤解、誤認識を解消) - 色々なところに散らばっているテストケースをまとめる(不要なものがどれだけある?テストの構成ってどうなってる?の確認) - ある案件に企画段階から参加してみる(理想の開発体制を模索) - ある既存機能に対してゴリゴリテスト設計してみる(できたものを今のテストケースと比較する、誰かに見せてみる) - QAというポジションとして、どうしていきたいのか社内発表してみる(啓蒙活動) etc… ※()中は意図
当時のメモ
改善に向けて考えるべきは多い。 ただ、ここまで問題のある組織だと、言葉の定義からどうにかしたくなった。 QAという言葉の意味は何なのか?
ここから、一般的な解釈を説明するために勉強会を開くことになります。
勉強会を見ていた人間から質問が飛びました。
「 結局、何する人なんですか? 」
質問の意図はQA、品質の話というより、今までのテストの内容ばかりでした。
発表した内容としては、
1. ソフトウェアテストの原則 2. よくあるアンチパターン 3. QAってもっと頭を使うことであること 4. 組織で品質を作り込んでいく必要があること 5. みんなで考えてみんなで自分たちなりの答えを出したいこと
のような内容だったのですが・・・
カラオケを終えただけで、発表の手応えをあまり感じませんでした。
説明をしても一向に伝わらない。何故なのか?
聞いてくれた方々の特徴がわかってきました。
すぐに例を求め、すぐに抽象度を下げたがる。 例を出しても結果的に同じ状況にならないと何もできない。 概念を理解して欲しいが、具体例に終始してしまう。
結果的に「何が言いたいのかわからなかった」とも言われる始末で衝撃を受けました。
- 説明が悪いのか?(多分よくはなかった) - 資料がよくなかったか?(多分よくはなかった) - 仮定した聴衆の視点が悪かったか?(多分よくはなかった) - ここまで何もできない人間だったか?(多分・・・)
自信をなくすことになるまで時間はかかりませんでした。
とはいえ、一部の理解者が現れます。
理解者の大切さ
何かしら感じ取ってくれた人達からは、こんなことを言われました。
- めっちゃ難しそうだけど面白そうですね。 - QAってわからないけど、会社としての品質を専門的に考えてくれる人? - 上流から入ってもらわないと品質保証って無理ですよね (企画の段階で入り込みやすいようにしてくれてありがとう。勝手にMTGに参加してみたりしたこともあったけど)
そういった周りの理解者が、その更に周りの人達を巻き込んでくれるありがたい状況だったりします。
人見知りおじさんが一生懸命いろんな人と話たりして頑張った結果
理解者が数人、十数人になっていきました。(数十人は自信ないから書かないけど)
心理的安全とかそういうことも必要ですが そもそも自分がどういうアウトプットができる人間なのか、どういうことをしていきたい人間なのかを話すことが大切なのかも。
現状
今の所の成果
- 会社の品質関連ドキュメント整備 - 開発フロー整備 - QA関連ドキュメント管理 - E2Eテスト自動化着手?(環境までは作った) - 「これリリースできない」っていったらMVPもらった
今後はやるべきことが多いので、色々な話をする機会が多いです。
話すことの一例としては、
- 品質をどう作り込むか考えたいな - テストをちゃんと考えたいなあ - UTの自動化あるけど、E2Eもやってみたいんだよね - 会社としてのミッション、ビジョンから、どういったプロダクトを作るとそれを達成できるようになるのかな? - ユーザーが使いにくいって思う部分ってなんだろ?
たまに何いってんの?みたいな顔もされますが、色々変わってきたなと感じます。
これが世に言う改善という話だったら、いい経験をしたのかもしれないですね。
とりあえず品質を組織的に作り込んでいく下地ができたのかもと感じる今日この頃です。
Akerunを設置するためにわざわざ3Dプリンタを買った新入webエンジニア社員の話
この記事は Akerun Advent Calendar 2019 - Qiita の1日目の記事です。
誰?
初めまして、今年の一発目を飾ることになりました。
4月にRoRエンジニアとして入社したdaikw - Qiita です。主にサーバ・webクライアント側の開発を担当しています。
3行で
どうしてもdogfoodingをしたくて自宅にAkerunProをつけました。
サムターンの形状が少し特殊だったため、3Dプリンタを買ってスペーサを作りました。*1
たのしぃ…
詳しく
Akerun Proの入手と絶望
弊社社員は、入社時の研修で渡されるAkerunPro一式をそのまま貸与されます。
個人的には、憧れのIoT代表格、スマートロック。
これは!!!つけるしかないでしょ!!!!
ちょうど一人暮らしを始めたところだし、新居にサクッと設置して物理鍵とオサラバしよう。
..., 神は死んだ。
3Dプリンタの入手と試し刷り
僕の部屋に神はいませんでしたが、3Dプリンタは格安で購入できることが分かりました。
造形方式はなんでもよかったのですが、
- メンテが比較的楽で *2
- ネット上のレビューで評価が比較的高く、
- それなりに安いもの
という基準で、ELEGOO MARSを選択。
")
樹脂はANYCUBICのグレーのやつにしました。
")
Amazonで注文すると、1週間ほどで配達。
試しに印刷してみた様子がこちら。


とても綺麗に印刷できますね。
あとサンプルモデルがイケてる。かっこいい。
サムターンのサイズ測定
本当は一般的なご家庭にあるノギスを使えば簡単なのですが、持ち合わせがなかったので、物差しを使って測ります。


サムターン部分のだいたいのサイズが分かれば良いです。画像から、
- 高さ: 15 mm程度
- 幅 : 30 mm程度
- 厚み: 3 mm弱
くらい
ちなみに、MIWAロックのLSPという型番らしい。

3Dモデルの作成
サムターンとAkerunProにちゃんと嵌るように、ざっくり作るとこんな感じ。
サムターン側は、余裕を持って幅を5 mmに。

印刷と設置
作成した3Dモデルから、stlファイルで出力し、ELEGOO MARS用のスライサ*3で印刷用ファイルを作成。
印刷して取り付けると、、、?
神か、、、
しばらく使ってみると
1ヶ月ほど使ってみた後のスペーサの様子:

初めは綺麗だった表面に、z軸と垂直な方向に亀裂が入っています。Additive Manufacturingの常なのかもしれませんが、レイヤ同士の結合が甘くなりがちなためです。
Akerunはかなり強いトルクを持っているので、このままだと割れてしまいそうです。設計を工夫して、応力が角に集中しないようにする工夫ができそうですね
まとめ
すりーでぃーぷりんたすごい
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 hrmos.co
Akerun Proの購入はこちらから akerun.com