Akerunバックエンドシステムの技術的負債に対する取り組み[後編]
この記事は Akerun Advent Calendar 2023 - Qiita の24日目の記事です。
こんにちは。@ps-tsh です。API Server などバックエンドシステムの開発を担当しています。前回に続き、当社(Photosynth)での技術的負債に対する取り組みについて紹介します。
前編はこちら:
2021年にスタートした技術的負債解消プロジェクトでは、メインの目的を「システムの安定稼働」と定め、安定稼働を実現するための取り組みとして「収集メトリクスの改善」「単一障害点の解消」「ソフトウェア脆弱性の解消」「運用作業の品質改善」の4方針でそれぞれ施策を実施していきました。
収集メトリクスの改善
最初に取り組んだのが「収集メトリクスの改善」です。正しい判断には正しい情報が不可欠だからです。前回触れたように、このあたりは外部サービスの導入やプラン変更で対応しました。2023年現在、アプリケーション性能監視(APM)ツールとして NewRelic、エラーの監視・トラッキングには Sentry、WebエンジニアとSREによるオンコール運用には PagerDuty などを利用しています。
障害対応が迅速に行えない原因の一つとして「機能のリリース時には問題に気づかず、数ヶ月後の状況変化で元からあった問題が顕在化する」というパターンがあります。APMツールの導入で、サービスが提供する機能のエラーやパフォーマンス遅延、処理全体におけるボトルネック箇所を早期に発見することができるようになりました。APMツールから得られる情報をもとに、パフォーマンス基準を下回るAPIレスポンスやSQLクエリのチューニングを実施しました。また、エラーの原因として「外部連携先のサービスがダウンした際の考慮不足」という傾向があることもわかり、こちらはエラーハンドリングを改良することで対処しました。
APMを使うとサービスの状況変化をリアルタイムで把握できるので、新機能のリリース時に性能問題があった際ただちに切り戻しの判断をすることができます。あわせて、エラー監視とオンコール運用の体制を整えることで、障害発生から対応完了までの期間を大幅に短縮することもできました。
単一障害点の解消
次は「単一障害点(SPOF: Single Point of Failure)の解消」です。Webサービスの運用においてはあらゆるトラブルを完全に予防することは困難であり、一部のエラーがシステム全体のダウンにつながらないような配慮が必要になります。当時のAkerunバックエンドシステムにも、以下のようなアーキテクチャ上の課題がありました。
リクエスト処理とバックグラウンドジョブを同じAPIサーバで処理していた
1つのAPIサーバにリクエスト処理とバックグラウンドジョブ処理の両方を担当させていたため、一方の負荷上昇がが双方に影響する構造になっていました。リソース逼迫の原因切り分けも困難であったため、専用の worker サーバを導入しリクエスト処理を行うサーバとバックグラウンドジョブを実行するサーバを分離することで解決しました。
重要度やアクセス特性の異なるリクエストを同じAPIサーバで処理していた
合鍵の権限更新やリモート施解錠など「常時安定して高可用性・低遅延が要求される重要機能」と、入退室履歴のダウンロードなど「利用頻度は高くないが負荷の高い機能」を同じAPIサーバで提供していました。
当時は入退室履歴のダウンロード機能が同期処理で実装されており、ユーザ数や利用ボリュームの増大によってAPIサーバにリクエスト処理プロセスが滞留し、同じAPIサーバで提供される他の機能もレスポンスが大幅に低下するといった問題がありました(現在は非同期処理への置き換えが完了し、データ生成はバックグラウンドで行っています)。APIサーバのクラスタと配置機能を見直し、リモート施解錠などの「重要機能」群とそれ以外の機能は別のクラスタで実行させるよう変更することで対応しました。
ソフトウェア脆弱性の解消
次は「ソフトウェア脆弱性の解消」です。すでにEOL(End of life)を迎えているもの、脆弱性が報告されているものが多数使用されていました。これは基本的にはライブラリのバージョンアップを地道に行なっていくことになります。EOLの確認には各種公式サイトや endoflife.date、ライブラリ脆弱性の確認には Github の Dependabot alertsを使っていました。
2021年時点のAkerunバックエンドシステムは恥ずかしながら Ruby 2.2 + Rails 4.1 で 運用されていました。Ruby, Rails ともは2020年以前にEOLを迎えており、セキュリティサポートが受けられない状態でした。また、Ruby/Rails のバージョンが古いせいで、新規に導入したい rubygem があっても要求バージョンを満たせず、自前でコピー実装を用意するなどの非効率な対応を余儀なくされていました。
他の機能開発も並行しながらの対応となったため最速・一括のアップデートというわけにはいきませんでしたが、何度かの段階的リリースを経て、2023年11月までに最新の Ruby 3.2 + Rails 6.1 にアップデートしました。一部サーバでは YJIT も有効にしてパフォーマンスアップの恩恵も享受できています。現在は Rails 7.0 へのバージョンアップ対応準備を進めています。
バージョンアップ対応を進める過程で、全APIのリグレッションテストを効率よく実施するサイクルを確立することができました。当初は手動テストの比率が高かったのですが、QAエンジニアによるE2Eテストの自動化なども進み、効率よく互換性を確認できるようになりました。
さらに、本番環境へのリリース前には毎回1週間程度のドッグフーディング(社内での試験運用によるテスト)も実施し、実運用に問題ないことを確認してから本番環境に適用しています。
運用作業の品質改善
最後は「運用作業の品質改善」です。「ユーザーに提供するための新機能開発を優先するあまり運用系の機能整備を後回しにしがち」というのはスタートアップによくある話だと思いますが、運用系の機能不足は大量のトイルを生み出します。これも一種の技術的負債であるといえるでしょう。
トイルとは、プロダクションサービスを動作させることに関係する作業で、手作業で繰り返し行われ、自動化することが可能であり、戦術的で長期的な価値を持たず、作業量がサービスの成長に比例するといった傾向を持つものです。 (SRE サイトリライアビリティエンジニアリング)
トイルの問題は「単調で退屈である」といったことにとどまりません。各担当者は一生懸命やっているにもかかわらず、経営層をはじめとするビジネスサイドからは全く成果が出ていないように見えるので、相互尊重の雰囲気が失われやすいという問題もあります。
運用作業の品質改善としては主に「手動オペレーションの自動化」「リリース関連のルール整備・作業記録の徹底」を行いました。
手動オペレーションの自動化
2021年時点でバックエンドアプリケーションのデプロイは既に自動化されていましたが、不定期に発生する「ファームウェア更新」「設定ファイル更新」などの運用業務の多くは手動で行われていました。dotfile に定義されたバージョン情報やファームウェアのバイナリなど、更新に必要なファイルをサーバに配置する必要があるのですが、手動作業の結果「複数台のサーバに同じ設定が反映されていない」「アップロードされたファイルの中身が違っている」など、たびたび作業ミスが発生していました。これらをすべてリポジトリで管理し、更新ファイルのハッシュ値チェックやサーバへのデプロイをCD/CDに組み込むことでオペレーションミスが発生しにくい形に置き換えました。
リリース関連のルール整備・作業記録の徹底
これまでも大きな機能開発についてはQAプロセスを経てリリースしていたのですが、リリース後の不具合対応など、細かいものについては担当者が対応して都度リリースしてよいという方針でした。その結果、「いつ」「誰が」「何を」リリースしたのかわからない状態で運用されていました。
また、データ更新をはじめとしたメンテナンス対応についても手順書や作業記録が残っておらず、担当者ごとの作業品質に大きなばらつきがありました。商用サービスとして成熟する過程においては頻繁な機能リリースの利便性よりも安定稼働が重視されるタイミングと判断し、思い切ってリリースを定期イベントにしました。いくつかのプラクティスを紹介します。
- ブランチ運用: git-flowをベースにしたブランチ運用ルールを導入した
- リリース内容共有会: リリースを原則週1回の定期イベントとし、その週のリリース内容を開発チーム全員に事前共有する会議体を設けた
- リリース手順書: リリース手順書のフォーマットを用意し、リリース内容、タイムライン、チェック項目などを事前にまとめる
- イレギュラー発生時の切り戻し手順もあらかじめ明確化しておく
- ペアオペレーション: 本番環境へのリリースやメンテナンス作業は単独作業を禁止、必ず2名以上で画面共有しながら行う
- 作業記録: リリース作業やメンテナンス実施時に出力されたログやスクリーンショットなどを収集し、ドキュメントとして残しておく
- トラブルシュートを行なった場合の対応内容も記述する
リリースプロセスとしてはやや重めの内容になりましたが、新規メンバー向けのトレーニング効果もあったと思います。また、作業記録は蓄積されることで信頼できるアーカイブとして機能します。現時点で3年弱の履歴が残っていますが、過去に実績のある作業の再現やトラブルシュートに役立つことも増えました。
おわりに
技術的負債は一度解消して終わり、といった性質のものではありません。また新しい課題や取り組みが出てきたら、このブログで紹介したいと思います。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
Akerunバックエンドシステムの技術的負債に対する取り組み[前編]
この記事は Akerun Advent Calendar 2023 - Qiita の23日目の記事です。
こんにちは。@ps-tsh です。API Server などバックエンドシステムの開発を担当しています。最近は一つのトレンドとして技術的負債との付き合い方をテーマとしたIT勉強会の数が増えてきた印象がありますね。今回は、当社(Photosynth)での技術的負債に対する取り組みとして、プロジェクトを推進するうえでポイントになったところをいくつか紹介したいと思います。後編は12/24公開です。
評価と優先順位づけ
まず、最も大切なポイントはいきなり作業に着手せず、技術的負債の評価と優先順位づけをきちんとやりきるというところでしょうか。「さあ負債を返済するぞ!」と、ここぞとばかりにリファクタリングやパフォーマンスチューニングを始めたくなる気持ちも理解できますが、まずは解決策でなく問題領域のほうに目を向けましょう。いくら足が速い人でも間違った方向に走っていけば、間違った場所に早く着くだけです。
「負債とは何なのか」「どこから解消すべきか」「どの程度できればOKか」を最初に固め、ゴール設定を明確にしましょう。また、課題感についてはプロジェクトチームや開発部門内に閉じず、社内でひろく共有しステークホルダーの理解を得ることも重要です。当社では2021年の夏に社内で技術的負債の解決プロジェクトを立ち上げましたが、最初の2ヶ月は課題の整理に費やしました(いま振り返ってもこの方針は正しかったと思います)。
今回は課題整理を行うための「物差し」として、AWSの Well-Architected frameworkの柱 を利用してみました。それまではさほど馴染みもなかったのですが、実際に使ってみることで「なるほどよくできている」と実感することができました。

このマトリクスを整理し、解決すべき課題をまとめていきます。
- 機能関連
- 一部の機能に、非効率な処理方式による低パフォーマンスや拡張性の欠如がみられる
- 手作業を伴う運用タスクが多く、人為的ミスを誘発する状態になっている
- ログ関連
- ログはそれなりに収集しているが整理されておらず、活用しにくい
- 通知・監視におけるノイズが多く、障害発生時のリアクションが遅れがち
- インフラ
- メンテナンス目的の再起動にもリスクがあり、安心して運用できない
- いくつかの単一障害点があり、部分的な障害がシステム全体に波及する状態
- ミドルウェア
最終的にこれらを「収集メトリクス改善」「単一障害点の解消」「ソフトウェア脆弱性の解消」「運用作業の品質改善」の4方針として打ち出しました。具体的な取り組みについては後編で紹介したいと思います。
十分なリソースを確保する
次に大切なことは「十分なリソースの確保」です。長い年月をかけて蓄積された技術的負債の除去は大変な仕事です。「仕事の合間に少しずつ」ではなく、メイン業務としてしっかり取り組む体制を整えることが成果につながると思います。「本業の裏で進めていたシャドウワーク的な取り組みが身を結んだ」というようなエピソードは格好良く聞こえますが、毎回エンジニア個々人の自発性に頼るべきではありませんし、意欲の高さがかえって疲弊感につながることもあります。実際の負債解消は長期戦・総力戦です。十分なスケジュールや工数を確保しましょう。
実はプロジェクト開始以前にもエンジニア有志によるRuby/Railsのバージョンアップの試みがあったのですが、結果としてはうまくいきませんでした。本務としてアサインされているプロジェクトが忙しくなってしまうとどうしても対応優先度は下がってしまいます。せっかく作った Pull Request もメンテナンスされず捨て置かれるという残念な状況が発生していました。そこで、負債解消のプロジェクトがスタートした後は、それぞれの取り組みにはできるだけ専任のメンバーをアサインし、対応に集中してもらえる体制を整えました。
また、ここでいうリソースとは対応メンバーといった人的リソースに限られません。我々もエンジニア組織として決して大きいわけではなく、全ての取り組みを自社メンバーだけで賄うだけの余裕はありませんし、スキルセットや得意分野の違いもあります。十分な効率が出せないなと思ったら、外部の商用サービスを積極的に利用するのも一つの方法です。我々のプロジェクトでは今回、パフォーマンス監視、エラートラッキングやインシデント管理の仕組みは内製せず、外部サービスを早期に導入しました。プロジェクト初期に監視ツール群を導入することで十分な情報にアクセスしながら以後の施策を効率よく進めることができました。
継続的なプロセス改善
最後は、ちょっと意外かもしれませんが「継続的なプロセスの改善」です。技術的負債の返済というと、既存コードの改修やライブラリ更新、外部ソリューションの導入といった形のソフトウェア的な解決をメインシナリオと考えがちですが、これまでの取り組みを振り返った感想としては、一番効いたのはプロセス改善系の取り組みだったように思います。技術的負債の総量を減らすためには、既存の問題を片付けるのと同時に新しい負債を生み出さないこともまた重要です。
我々のチームでも「手動オペレーションの自動化」「リリース関連のルール整備」「作業記録の徹底」などいくつかのプロセス改善に取り組みました。特にリリースまわりのルール整備による作業品質の向上は、サービスの安定稼働に大きく貢献できたのではないかと思います。
近年のアプリケーション開発におけるツールの発達や生産性向上には目覚ましいものがありますが、いっぽうで作ったものを長期間・安定的に運用できるノウハウを持つエンジニアはあまり多くないように思います。私個人は過去の職歴も含めると10年以上 SaaS の会社で働いてきたこともあり「これくらい当たり前だろう」と思っていたこともあったのですが、改めて知識や経験をチームに展開する大切さを実感しました。
おわりに
前置きが長くなってしまいましたが、大きな課題に取り組みには適切な問題設定が欠かせません。前編はこのへんにして、次回(12/24公開)は具体的な取り組みや成果について紹介したいと思います。
後編はこちら: akerun.hateblo.jp
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
[SwiftUI]テスタブルな画面遷移の実装手順
こんにちは、 takeshi-p0601 - Qiita です。普段iOSアプリケーションの開発をメインに業務を行っています。AdventCalender今年2回目の参加です。
本記事ではiOSアプリに関する実装の小技を紹介します。具体的にはSwiftUIでアプリを実装するにあたって、最近試している画面遷移の実装をする際のちょっとした工夫です。内容的にiOS/iPadOSのアプリケーションを開発される方向けの記事になります。
画面遷移の実装
あるA画面から、B画面に遷移するような要件を実装する場合、SwiftUIを使用してどのように実装しますか? UIKit時代のViewControllerと違って、SwiftUIではViewControllerに相当するものが値型となってしまったせいで、UIKitで実装可能だったViewControllerにおける遷移関連の処理を別クラスに委譲させるような、そうした実装はしづらくなりました。
とはいえSwiftUIを使って実装する場合でも、ある程度責務を分けながら実装したいと考えていました。 その中で考えついた実装を紹介します。
まず必要な構成要素は下記三つです。
- XXXView: 画面
- XXXViewEventHandler: 画面から来たイベントを受け取るオブジェクト
- 直近巷で目にふれる、iOSアプリ文脈のアーキテクチャパターンではあまり見ない命名ですが、いわゆるMVPパターンのPresenterやMVVMのViewModel等の責務に近い現場などあるかもしれません。
- XXXViewRouter: あるViewのアクティベート(ある画面を表示することとします)依頼を受け取ったら、そのViewを作成しつつそのViewを表示させることを、参照元に通知させるオブジェクト
それら構成要素を合わせて、A画面からB画面に遷移するような、処理シーケンスは下記のようなイメージです。

実装方法
※下記の前提があるため、その認識で読み進めてください。
- わかりやすくするために、あえて命名にアンダースコアをつけている箇所があります
- 基本的にプッシュ遷移を想定した説明ですが、モーダル遷移でも適用可能です
- 状態管理の実装をするための知識はある前提で、特に補足せず記載しています
まずRouterを作ります。RouterはViewとEventHandlerどちらからも参照されるものです。
@MainActor protocol A_ViewRouterable { var isB_ViewActivated: Bool { get } var activatedB_View: B_View? { get } func activateB_View() } class A_ViewRouter: ObservableObject, A_ViewRouterable { @Published var isB_ViewActivated: Bool = false var activatedB_View: B_View? { self._activatedB_View } private var _activatedB_View: B_View? = nil func activateB_View() { self._activatedB_View = B_View() self.isB_ViewActivated = true } }
@Published var isB_ViewActivated: View側に変更を通知させるための変数です。あらかじめViewがこの変数の変更を監視します。var activatedB_View: B_View?: アクティベートされた際にView側に参照してもらうための変数です。このRouterクラスではViewの生成も担いますfunc activateB_View(): イベントハンドラーから、アクティベート依頼するためのインターフェースです。今回は特に存在しませんが、例えばB_ViewがA画面からの値を受け取る必要がある場合、このメソッドに引数を持たせるイメージです。
続いてEventHandlerです。
@MainActor protocol A_EventHandable { func tapGoB_ViewButton() var a_viewRouter: A_ViewRouterable { get } } class A_EventHandler: A_EventHandable { let a_viewRouter: A_ViewRouterable init(a_viewRouter: A_ViewRouterable) { self.a_viewRouter = a_viewRouter } func tapGoB_ViewButton() { self.a_viewRouter.activateB_View() } }
先ほど定義した、Routerを保持します。そしてtapGoB_ViewButton() が実行された際に、 B_ViewをアクティベートするようにRouterに依頼します。
最後にA_Viewです。
import SwiftUI struct A_View: View { @StateObject var a_viewRouter: A_ViewRouter var eventHandler: A_EventHandable var body: some View { VStack { Button("Go to B") { self.eventHandler.tapGoB_ViewButton() } } .navigationDestination(isPresented: self.$a_viewRouter.isB_ViewActivated, destination: { self.a_viewRouter.activatedB_View }) } }
下記の部分でRouterの変数の値の変更を監視しつつ、アクティベートされたタイミングでPush遷移させるようにViewを挿入します。
.navigationDestination(isPresented: self.$a_viewRouter.isB_ViewActivated, destination: { self.a_viewRouter.activatedB_View })
構成要素の実装としては、以上で終わりです。
そして最後に重要なことはA画面の生成の実装です。言ってしまうとなんてことありませんが、 ⭐️印で生成したrouterを、A_ViewとEventHandlerがそれぞれ同じ値に依存するように、初期化時にセットしてください。
func activateA_View() { let router = A_ViewRouter() // ⭐️ self._activatedA_View = A_View(a_viewRouter: router, // ここ eventHandler: A_EventHandler(a_viewRouter: router)) // ここ self.isA_ViewActivated = true }
RouterインスタンスをA_Viewと、EventHandler向けにそれぞれ作成してセットする場合、ViewからEventHandlerをトリガーにしたRouterの値の変更を監視できず、結果画面遷移できない状況が発生します。
効果
EventHandler側は、何をアクティベートさせるかに焦点を当てるような実装をすることが可能で、Router側に画面の生成やアクティベートに必要な変数を管理してもらうことで、ややスッキリしたと思います。
またあくまでロジック上ですが、下記のようにEventHandlerのイベントから画面がアクティベートされているかテストできるようになり、今回の修正を適用しない場合に比べてテストしやすい部分が増えることが期待できます。
import XCTest @testable import MyApp final class MyAppTests: XCTestCase { @MainActor func test() { let router = A_ViewRouter() let eventHandler = A_EventHandler(a_viewRouter: router) eventHandler.tapGoB_ViewButton() XCTAssertNotNil(router.activatedB_View) XCTAssertEqual(router.isB_ViewActivated, true) } }
[応用]アラートを表示する実装
iOS/iPadOSにおいて標準で表示できる、アラートについても今回の実装を適用できます。経験上アラートのプログラムは油断しているとView側やEventHandler側に増えがちになるので、必要に応じてRouter側に寄せることも一つ手だと思います。
RouterではAlertItemを生成し、それをアクティベートさせることを担っています。
struct A_ViewAlertItem: Identifiable { let id = UUID() let type: AlertType enum AlertType { case networkError(title: String, message: String, okButtonTitle: String) case otherError(title: String, message: String, okButtonTitle: String) } } @MainActor protocol A_ViewRouterable { var isB_ViewActivated: Bool { get } var activatedB_View: B_View? { get } func activateB_View() // アラート var alertItem: A_ViewAlertItem? { get } func activateNetworkErrorAlert() func activateOtherErrorAlert(message: String) } class A_ViewRouter: ObservableObject, A_ViewRouterable { @Published var isB_ViewActivated: Bool = false var activatedB_View: B_View? { self._activatedB_View } private var _activatedB_View: B_View? = nil @Published var alertItem: A_ViewAlertItem? = nil func activateB_View() { self._activatedB_View = B_View() // 1 self.isB_ViewActivated = true // 2 } func activateNetworkErrorAlert() { self.alertItem = A_ViewAlertItem(type: .networkError(title: "エラー", message: "サーバーとの通信に失敗しました。\nやり直してください。", okButtonTitle: "OK") ) } func activateOtherErrorAlert(message: String) { self.alertItem = A_ViewAlertItem(type: .otherError(title: "エラー", message: message, okButtonTitle: "OK") ) } }
ViewがRouterの変更を監視しつつ、変更があった際にアラートを表示させます。
import SwiftUI struct A_View: View { @StateObject var a_viewRouter: A_ViewRouter var eventHandler: A_EventHandable var body: some View { VStack { Button("Go to B") { self.eventHandler.tapGoB_ViewButton() } } .navigationDestination(isPresented: self.$a_viewRouter.isB_ViewActivated, destination: { self.a_viewRouter.activatedB_View }) } .alert(item: self.$a_ViewRouter.alertItem, content: { alertItem in switch alertItem.type { case .networkError(let title, let message, let okButtonTitle): Alert(title: Text(title), message: Text(message), dismissButton: .default(Text(okButtonTitle))) case .otherError(title: let title, message: let message, okButtonTitle: let okButtonTitle): Alert(title: Text(title), message: Text(message), dismissButton: .default(Text(okButtonTitle))) } }) }
SwiftUIのアラートは下記で示されている通り、連続してmodifierを使用して実装することができません。そのためAlertTypeを定義することでその問題を解消させながら、今回の実装を適用してみました。
https://stackoverflow.com/questions/58069516/how-can-i-have-two-alerts-on-one-view-in-swiftui
先ほどのViewの画面遷移の実装と同様に、アラート部分についてもテストしやすさが増すと思いますのでぜひ試してみてください。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
設計ドキュメントとソースコードについて思うこと
こんにちは。 Esperna - Qiita です。 私は組み込みLinux製品の開発を行なっています。 今年は錠制御に関わるシステムを主にnodeJSで開発していました。
前回はE2Eテストについて書きましたが 今回は設計ドキュメントとソースコードについて思うことについて書きます。 「ソースコードは設計書であり、プログラミングが設計作業である」という意見について、私は正しいと思っています。 一方で、開発をスケールさせていくことを考えると、一定設計ドキュメントを残すべきではないかとも思っています。
今回、設計ドキュメントとソースコードという観点でみた時に 自分のこの一年の開発はどうだったのか?振り返ってみました。 開発としては設計ドキュメントを残し、設計と実装のトレーサビリティを取る開発をしていました。
ここでいう設計ドキュメントとは具体的にクラス図、状態遷移図、シーケンス図を指します。
よかった点
- 不具合があった時にこのクラス図(あるいはシーケンス図)のここを直せば良いということをチームメンバに伝えやすい
- 複数人で設計の妥当性を議論する際に、クラス図(あるいはシーケンス図、状態遷移図)があるとチーム内で認識を合わせる際の助けとなる
- これらの図がない状態で議論をすると、各人の認識にズレが生じやすいことがあるように思われる
- 個人が作業する上での外部記憶として便利である
- 個人のスキルや脳内記憶容量にもよりますが一定の規模より大きい設計になると、クラス図(あるいはシーケンス図、状態遷移図)があった方が設計・プログラミングをし易いと思われる
- 一定の規模より大きくなったら分割してイテレーションを回すのがセオリーだが結局全部の要素の組み合わせを考えなければ設計できないこともあるように思われる
- 後になって書かなければいけないという理由で、設計書を書くという作業(単体テストを後から書いてカバレッジだけ通すような作業)がなかった
- 設計を行う過程のアウトプットとして書くことができた
- 時間をかけて設計した分、設計そのものがひっくり返るような大きな手戻りはなかった
- 成果物がdocやspread sheetではなくplantumlでgithubを使って、バージョン管理とPRで運用できたのはよかった
悪かった点
- 実装に近いレベルでシーケンス図を書いてしまうとちょっとした変更で設計ドキュメントのメンテナンスコストが発生した
- もう少し抽象度を上げたシーケンス図にすべきだった
- ドキュメントが多いと他者がドキュメントを探す・理解するのに時間がかかった
- これはドキュメントの整理の仕方に改善の余地があることを示唆していると思われる
- 設計ドキュメントを書くことに時間をかけるよりも、ある程度の時点で実装して動かしてみることで別の視点に気づけると思われる部分もあった
- モジュール境界のI/Fを説明するドキュメントが足りないと感じた
- これは個人のこだわりに近い部分があるかもしれないがgodocのようなドキュメントを残したかった
- モジュール境界のI/Fにこだわるのは前述のE2Eテストを補強するため
今後について
開発をスケールさせていくことを考え、皆が一定設計ドキュメントを残すということを考えると、 要求が比較的固定的なプロジェクトでは、以下に絞ってドキュメントを残すのは一定意味があるのではと思いました。
- モジュール境界のI/F
- クラスの責務分担
- 主要なシナリオレベルのシーケンス図(必要なら状態遷移図)
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
リファクタリングの効果を可視化したい
この記事は Akerun Advent Calendar 2023 - Qiita の19日目の記事です。
はじめまして。SW開発部の @yooda です。Photosynthに入社して1年半ほどになります。 BtoC 向けのサービス開発として MIWA Akerun Technologies と一緒に開発をやっています。
はじめに
ソフトウェア開発のエンジニアをやっていると、自分たちが開発し、保守しているシステムのプログラムのリファクタリングをする機会が度々発生します。
リファクタリングとは、外部から見た時の挙動は変えずに、プログラムの内部構造を整理することです。 リファクタリングの目的には、プログラムの可読性を上げたり、処理の効率化・高速化を行ったり、といったものがあります。
エンジニア目線では、リファクタリングという作業は、プロダクトの品質を維持して、継続的に安定した運用ができるように改善していく大事な作業です。
しかし、プロダクトをマネジメントし、エンジニアに投資する立場の人には、見た目の変化が発生しない作業を把握できずに、工数を使っている割に生産量があがらないと見えることもあります。
開発を推進するリーダーの立場として、開発メンバーが安定したシステムを維持するための活動の価値を理解もらうためにどうしたら良いかを考え、実践していることについて書きたいと思います。
リファクタリングの効果
まずは、リファクタリングの活動がプロダクトにどういう効果をもたらすかを考えました。
リファクタリングを行うことで、プロダクトの品質が向上し、継続的に利用可能なシステムを維持できることに繋がります。 品質の観点でプロダクトを分析すれば、なにかしら可視化への道が見えてきそうです。
そこで、ソフトウェア品質について定めたJIS規格 JIS X 25010:2013 の製品品質モデルを引用して、 リファクタリング作業と紐付けしてみます。
| リファクタリング | 得られる効果 | 品質特性 | 品質副特性 |
|---|---|---|---|
| プログラムの可読性の向上 | コードを把握しやすくする | 保守性 | 解析性 |
| 処理の高速化 | 性能改善の効果 | 性能効率性 | 時間効率性 |
ソフトウェアの品質の保守性や性能効率性の観点において、リファクタリングの効果を表現できそうです。
現状の品質を分析
私が開発を推進しているプロダクトについて、製品品質モデルを元に品質分析を行いました。 その結果、改善していくべき課題が浮かび上がってきました。
その中で、以下の品質特性 | 品質副特性に着目し、現在抱える課題について考察しました。
- 保守性 | 修正性
- ある不具合の修正を行った結果、思わぬ副作用により別の処理に影響を与えて、別の不具合を誘発したケースが何度か発生した。
- 保守性 | 解析性
- 発生した不具合の調査を進める際に、解析に十分なログが残っておらず、ログの追加・再テストを行ったため、工数を多く消費した。
こういった現状のプロダクトに潜在する品質課題を明確にして、この品質課題の解決を目的に改善を進めていき、 デグレ発生数の減少、解析時間の短縮化を成果として見せることで、リファクタリングの効果を可視化できると考えました。
さいごに
元々は、リファクタリングの効果を可視化することを目的として品質分析を実施しましたが、 実際にやってみた結果、プロダクトが抱える課題を俯瞰的に把握することができました。 先ほど挙げた品質特性は、リファクタリングで改善できる点に着目したものですが、 それ以外の品質特性でも改善したい項目が発見されました。
こういった品質分析は、プロダクトの健康診断のような意味合いを持つと感じました。 今現在は問題がなくても、時間の経過とともに小さな問題が膨れ上がり、大きな問題に発展することもありえます。
リファクタリングの作業は、プロダクトが抱える顕在化していない課題を未然に解消し、 プロダクトが長く健康な状態を維持できるために必要な作業であることを自身でも実感できました。
この活動をプロダクトをマネジメントする方にも共有して、その価値を感じてもらえるよう、 今後も継続していこうと思います。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
15億件以上入ったテーブルのスキーマをサービス無停止で変更した
こちらは、Akerun Advent Calendar 2023 18日目の記事です。
はじめまして、今回はWEBエンジニアの @yuto_a が担当させてもらいます。
今年の春から夏にかけて、15億以上のデータが入ったMySQLテーブルのスキーマ変更をサービス無停止で実施しました。 今回はこの対応を実施した私が、そもそもなぜサービス無停止でのスキーマ変更が必要だったのか、どのようにサービスを止めずにスキーマ変更したのか、実際に使用したときに工夫したポイントについて共有します。
サービス無停止でスキーマ変更した理由
そもそもなぜサービス無停止でのスキーマ変更が必要だったのか?
我々のサービスでは、APIサーバーに Ruby on Rails (以下、Rails) を使っており、データベースには AWS Aurora MySQL 5.7互換 を使っています。 このアプリケーションは Rails のバージョンが低いときに作られ、アップデートを重ねて今では Rails 6.1 で稼働しています。
Rails 5.0 以前に作られたMySQLテーブルのほとんどは、PKであるidカラムの型がINTEGERとなっています。
というのも、Rails 5.1 で主キーのデフォルト型が BIGINT に変更され、それより前はデフォルト型がINTEGERであったためです。
そのため、主キーが INTEGER型になっているというのは、歴史の長い Rails アプリケーションではわりとある話ではないかと思っています。
では、idカラムの型がINTEGERだと何が問題なのか?
INTEGER型の上限値は約21億 (231-1) であり、その上限値に到達した場合は新たなレコードが作成できなくなってしまいます。
実際、我々の使っているテーブルでデータ件数が15億に到達し、年2-3億のペースで増えているため、数年以内に上限値に到達してしまう状況でした。
そこで我々は idカラムの型をBIGINT UNSIGNEDに変更することで上限値到達のリスク回避を行いました。
型を INTEGER から BIGINT にすることで、上限値は約21億 (231-1) から 約920京 (263-1) になります。
さらに id カラムはAUTO_INCREMENTで増え続けるだけで負の値は不要であるため、BIGINT UNSIGNED にすることで、上限値は約1800京 (264-1) まで引き上げられます。
ですが、MySQLにおいてカラムのデータ型変更にはテーブルの再構築が必要で、その間テーブルがロックされます。
(MySQL :: MySQL 5.7 Reference Manual :: 14.13.1 Online DDL Operations)
先にも書いた通り15億件以上ものデータが入ったテーブルがあり、そのテーブルに対して普通にALTER TABLEでスキーマ変更しようとすると、サービスが長時間停止してしまいます。
しかし、我々はスマートロックのサービスを提供しており、サービス停止により鍵の開閉等に影響がでてしまうため、サービスの停止時間は可能な限り短くしなければなりません。
ためしに見積もったところ数時間程度の計画メンテナンスの時間に収まらないことが予想されたので、普通に ALTER TABLE でスキーマ変更する方法は選択肢から外れました。
そのため、サービス無停止でのテーブルスキーマ変更が必要でした。
サービス無停止でスキーマ変更した方法
では、どのようにサービスを止めずにスキーマ変更したのか?
結論からいうと、pt-online-schema-change というツールを使いました。 このツールは、Percona社が開発しているMySQLのツール群 (percona-toolkit) に同梱されているツールの一つです。 MySQLのDDLをオンライン実行するためのツールで、中身は Perl で書かれたスクリプトです。
以下のような理由で、pt-online-schema-change に決めました。
- サービスを止めることなくスキーマ変更が可能
- 我々の環境で使用可能 (Aurora, MySQL 5.7)
- 他社での実績がブログ等で公開されていて参考にできる
- インストールが簡単
- バイナリログの設定変更が不要 (似たツールで gh-ost というのがあり、そちらはバイナリログを使うため、バイナリログの設定に条件あり)
pt-online-schema-change がやっていること
pt-online-schema-change がどのようにDDLのオンライン実行を実現しているか説明します。
- スキーマ変更対象 (以下、旧テーブル) と同じスキーマの新規テーブル (以下、新テーブル) を作成します。
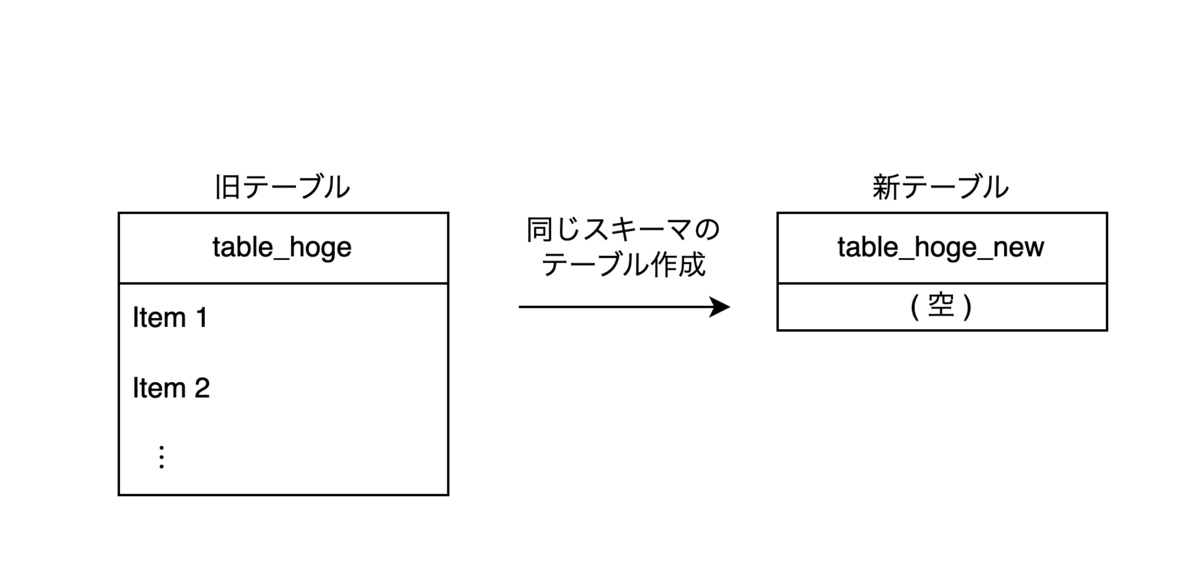
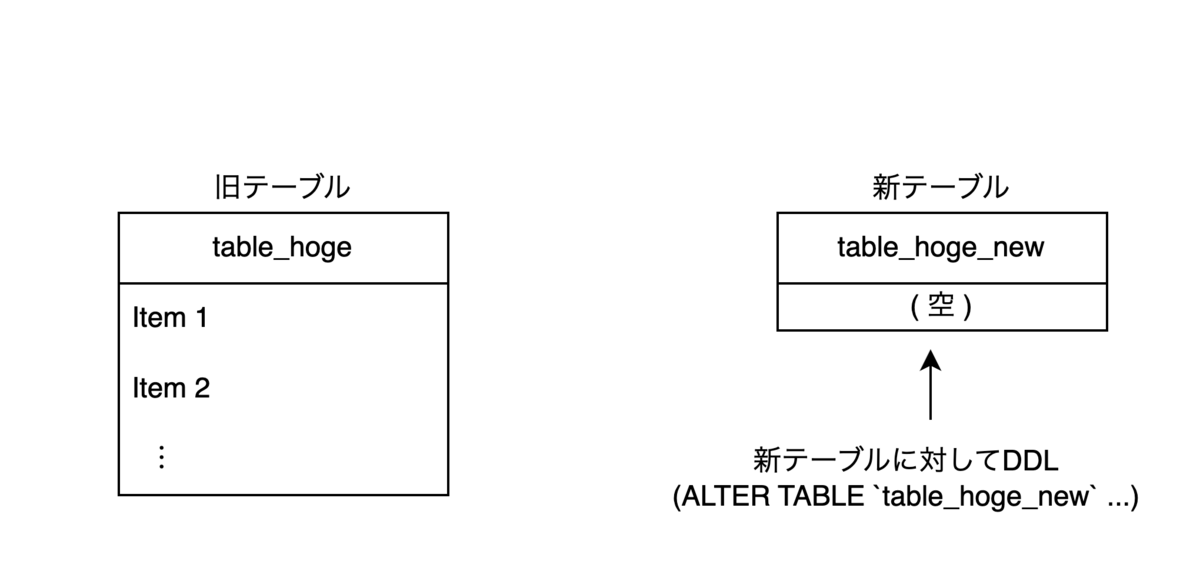
- 新テーブルに対して、DDLを実行します。この時点で新テーブルは空なので、DDLは一瞬で完了します。
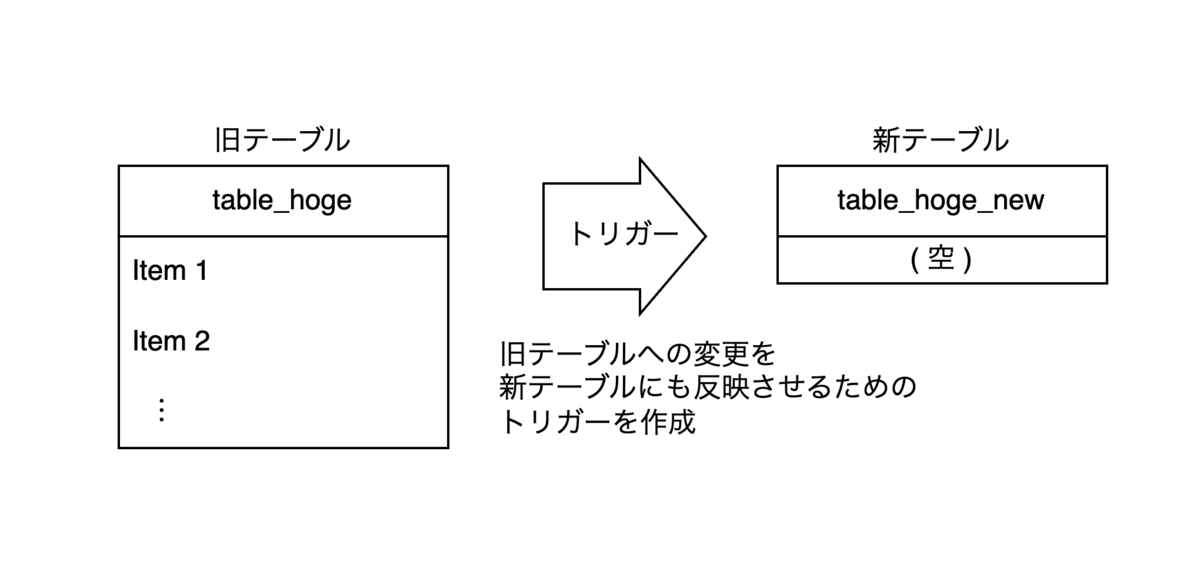
- 旧テーブルから新テーブルへデータの変更を反映するための、トリガーを作成します。このトリガーによって、旧テーブルへのデータの作成・削除・更新が新テーブルへ反映します。
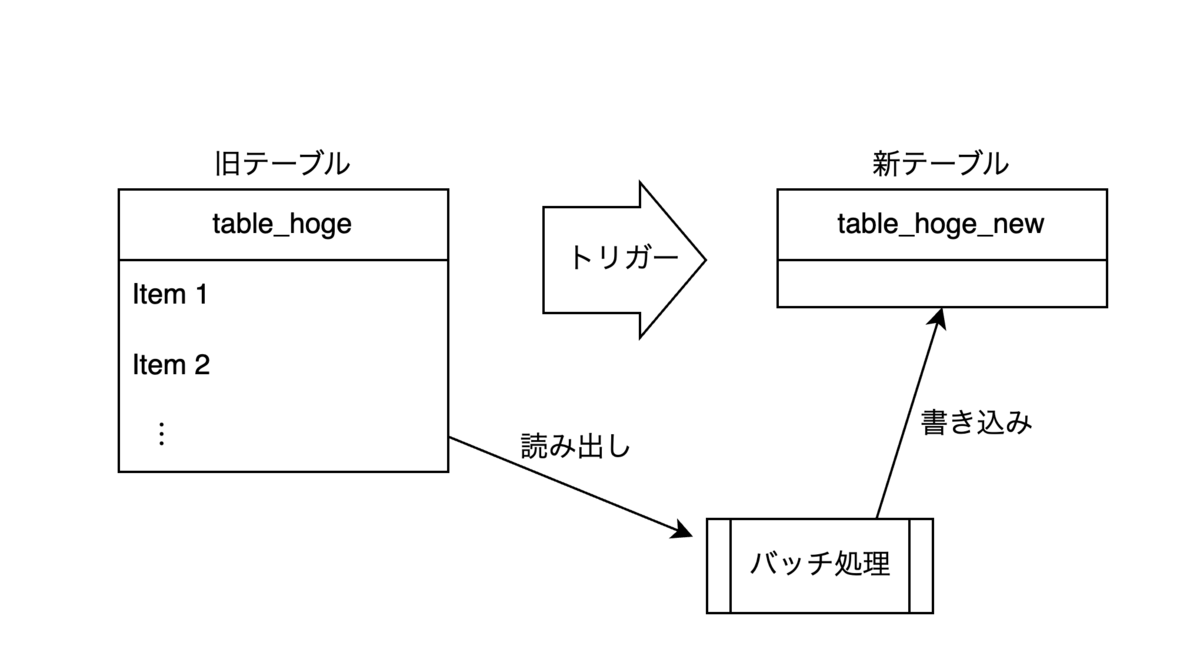
- 既存のデータをコピーするため、旧テーブルから読み出し、新テーブルへ書き込む処理が実行されます。
- 4.のデータコピーが完了すると、新テーブルと旧テーブルを
RENAME TABLEによって入れ替えます。これによって、元のテーブル名で新しいスキーマのテーブルが利用できるようになります。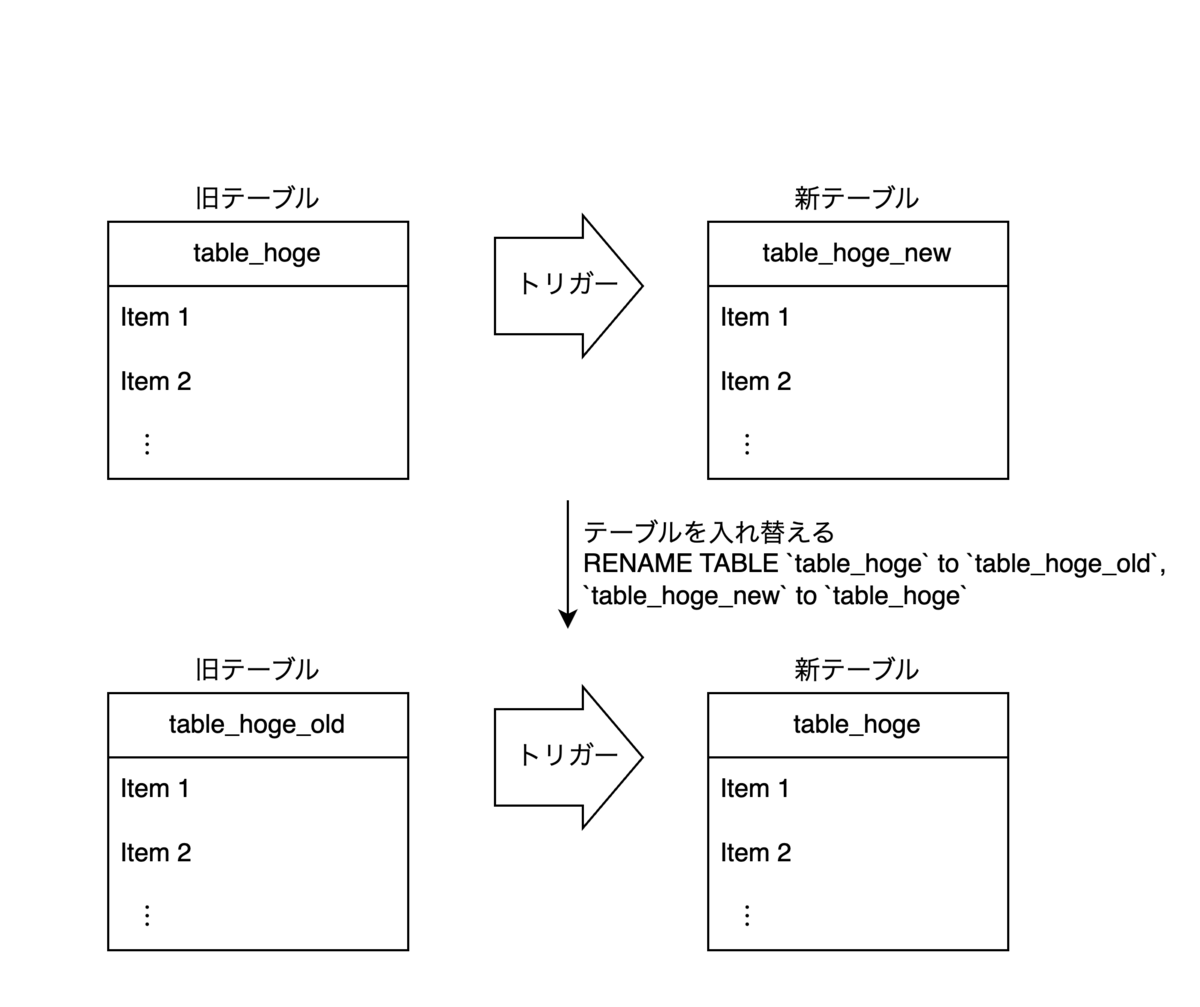
- 後片付けとして、旧テーブルの削除とトリガーの削除が行われます。

上記のような手順を経て、テーブルに長時間のロックをかけることなく、スキーマを変更することができます。
しかし、気を付けるポイントもいくつかあります。
- 大量の読み込み/書き込みを行うので、CPUやIO等の負荷はそこそこ上昇する
- トリガーの作成/削除、テーブル入れ替え時にロックがかかる
- トリガーによるオーバーヘッド
- リードレプリカがある場合、それらの遅延
- 外部キー制約がある場合、それらの対応を考える必要がある (というオプションで指定)
- 新たに UNIQUE制約を加える場合、データ消失のリスクがある
気を付けることは何点かありますが、基本的にはツールを起動してしばらく待っているだけでスキーマ変更が完了するので、非常に便利なツールです。
実際に pt-online-schema-change を使用してスキーマを変更
実際に本番環境のMySQLテーブルのスキーマ変更をするときに、次の点を工夫しました。
- 本番環境に近い環境での動作検証
- サービスの特性に合わせた移行戦略
実際に本番環境のMySQLテーブルのスキーマ変更を実施する前に、本番環境に近い環境として本番環境のMySQLのクローンを用意し、そこで動作検証を行いました。 クローンの作成については、AWS Aurora を使っていれば非常に簡単で、クラスターを選択して「アクション」から「クローンの作成」を選ぶだけでした。 また、検証後の後片付けも簡単でクローンしたクラスターを削除するだけです。
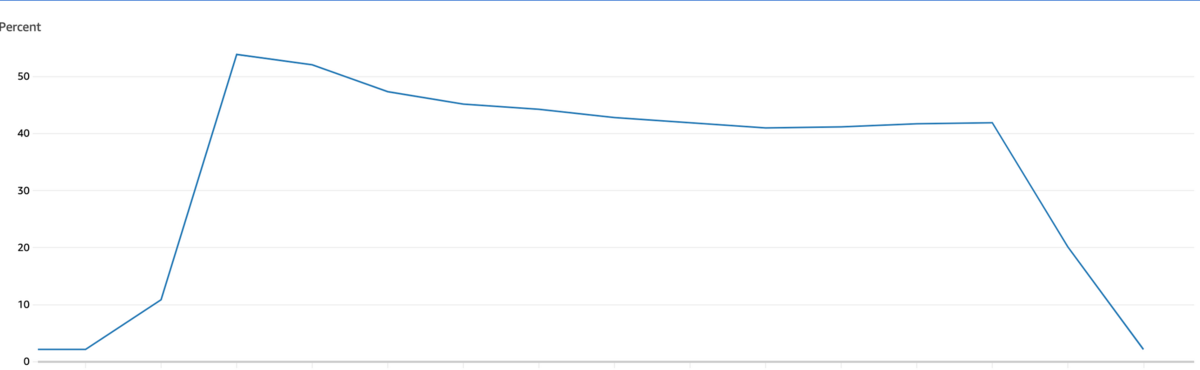
クローンしたDBで pt-online-schema-change を使ってみて、ツールの使用感やツール実行中の負荷状況、実施にかかる時間等を調べました。 また、各種オプションの指定方法や動きを確認したり、リードレプリカの遅延等の影響も確認しました。 これらの動作検証により、DBインスタンスのCPU使用率が最大で50%程度上昇することがわかりました。
我々のサービスはその特性上、日中のトラフィック量が大半を占めていて、夜間は極めて少なく、それに比例してDB等のリソース使用率も変動し、夜間のリソースにはかなり余裕があります。
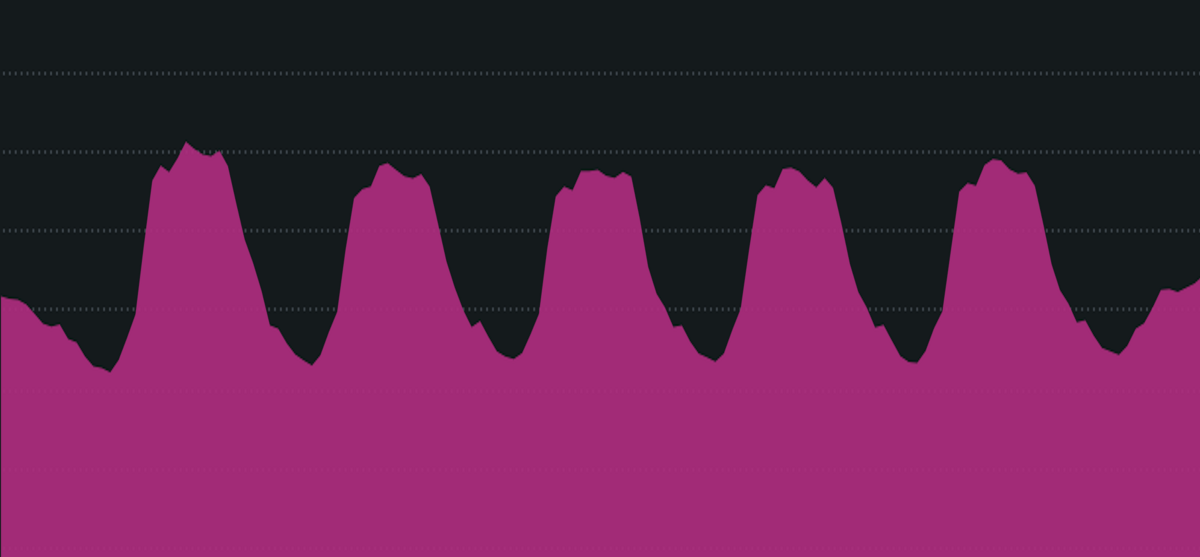
そのことを踏まえて、夜間のトラフィック量が少ないときのみ pt-online-schema-change によるデータコピーを実施し、日中は停止しておくという方法を採用しました。
具体的な方法としては、pt-online-schema-change の一時停止オプションとcronを組み合わせて、シンプルに実現しました。
pt-online-schema-change には一時停止用のオプションとして、--pause-fileというオプションが用意されています。
このオプションではファイル名を指定し、指定したファイルが存在している間は、pt-online-schema-change によるデータコピーを停止するというものです。
(トリガーによるデータの反映は継続します。)
このオプションで指定したファイルを、cronを使って作成したり削除したりすることで、pt-online-schema-change によるデータコピーの実行時間帯をコントロールしました。
cronは以下のような設定を使いました。
00 06 * * * touch /tmp/ptosc-pause-file 00 00 * * * mv /tmp/ptosc-pause-file /tmp/ptosc-pause-file-old
先述の動作検証含めしっかりと準備をした上で、本番環境のDBに対して pt-online-schema-change を使ったスキーマ変更を実施しました。
データ量がそこそこあること、夜間のみの稼働としたことで、1週間程度の時間が必要でしたが、無事に完了することができました。
これにより、idカラムがBIGINT UNSIGNEDになり、上限値到達のリスクを回避することができました。
まとめ
- pt-online-schema-change を使えば、簡単にオンラインスキーマ変更が可能
- CPUやIO等にそこそこ負荷がかかるので、そこはケアする必要がある
- 一時停止オプションがあるので、トラフィック状況に合わせて稼働させる時間帯を調節した
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
Akerunコントローラーからwebhookする
目次
初めに
みなさんこんにちは、naritakuです。本日はAkerun Adveent Calender 2023 16日目の記事です。前回のAkerunコントローラーのスマートプラグ化 に引き続き、Akerunコントローラーの改造第二弾です。
Akerunコントローラーは既設の電気制御のドアやゲートに簡易工事だけで設置し、直接制御できるスマートロックです。
Akerunコントローラーはドアの錠ともネットワークとも有線で接続されています。 そのため、ゲートウェイ端末とのBLE通信必要とするAkerun Proに比べ、よりリアルタイムに遠隔から施錠、解錠できる利点があります。
Akerunコントローラーの場合
sequenceDiagram
actor User
participant ctl as Akerunコントローラー
User->>ctl:遠隔解錠のリクエスト
activate ctl
ctl->>ctl: 繋がれた錠を解錠
deactivate ctl
Akerun Proの場合
sequenceDiagram
actor User
participant remote as Akerun Remote
participant akerun as Akerun Pro
User->>remote:遠隔解錠のリクエスト
activate remote
remote->>akerun: BLE通信による解錠リクエスト
deactivate remote
activate akerun
akerun->>akerun: サムターンを回して解錠
deactivate akerun
素早く応答できるなら、「扉が開いたことに連動してリアルタイムにXXXがしたい!」といったご要望にも応えたいですよね。 ということで、Akerunコントローラーの開閉をリアルタイムに通知すべく、webhookを仕掛けて遊んでみます。
やってみる
今回やりたいこと
Akerunコントローラーは既存の機能として開閉後に履歴のアップロードをしています。開閉を検知したらwebhookとして事前に登録したURLにデータを渡したいです。
sequenceDiagram
actor User
participant ctl as Akerunコントローラー
participant Server as 外部のテスト用のサーバー
User->>ctl: 解錠リクエスト
activate ctl
ctl->>ctl: 認証
opt 認証成功
ctl->>ctl: 解錠
ctl->>Server: webhook!
end
deactivate ctl
webhookとは?
HTTPリクエストを使って他のサービスにイベントの発生を伝える仕組みです。
- 単純なHTTPリクエストなので、扱える環境が幅広い。
- ポーリングに比べ、効率的に通信できる
などの利点があります。
詳細は
が勉強になりました。
webhookのあるあるを知りたい
webhookの雰囲気を掴むため、webhookの機能を提供しているサービスのドキュメントを眺めてみます。outgoing webhookと呼ばれている、ユーザーの指定したサーバーへ各webサービスから通知する方向のサービスをいくつか記載します。 LINEやGitHub、PayPayなど、生活に密着した様々なサービスが提供されていますね。
| サービス | できること | ドキュメント | なりすましの対策としておすすめしていること |
|---|---|---|---|
| LINE | botアカウントへの友だち追加や メッセージ送信などのイベント通知 |
メッセージ(Webhook)を受信する | リクエストボディーのHMAC-SHA256によるハッシュ値と リクエストヘッダーのx-line-signatureとして通知される署名を使ったHMACの検証 |
| GitHub | 事前にサブスクライブしたGitHubで発生するイベント通知 | Webhook のイベントとペイロード | Webhook の使用に関するベスト プラクティス |
| Meta | MessengerやInstagram,WhatsAppなど 各種サービスのイベント通知 |
スタートガイド - Meta Webhooks | SHA256のハッシュ値での認証 |
| PayPay | 支払い関連のイベント通知 | PAYPAY API docs | IPアドレスのホワイトリスト登録 |
| Paidy | 決済フローに進展があったことの通知 | Webhookとは | |通知のあった決済IDを使い、APIサーバーへ詳細な決済情報を再度問い合わせ検証 |
webhook自体は簡単に通知を送信できてしまうため、なりすましの対策は各サービスともに考えられています。 また、webhookを受信できなかった場合のリカバリーとして webhookの再配信をする仕組み等もあるようです。
webhookを使ったサービスでも、求められる要件で必要とされる機能は変わりそうですね。 実際にAkerun入退室管理システムとしてwebhookの通知をする場合は、Akerun APIの履歴取得API を補完するような機能にできると良さそうです。
錠の開閉をwebhookで通知してみる
先ほどのoutgoing webhookに対して、incomming webhookと呼ばれている、ユーザーから各サービスのエンドポイントへ通知するwebhookのサービスを提供しているサービスもいくつか探して連結させてみます。
ワークフロー系のツールやチャットツールが多いですね
| サービス | できること | ドキュメント |
|---|---|---|
| GoogleChat | チャットへの通知 | Google Chat アプリを Webhook として作成する |
| Slack | Slack ワークフローの発火 | Webhook で開始するワークフローを作成する |
| n8n | ワークフロー自動化ツールのトリガー | ウェブフック|n8n ドキュメント |
試しにslack workflowに錠の開閉を通知してみます。 Akerun APIと共通になるいくつかのパラメータを変数として通知できるようにしてみます。
{
action: 'unlock' または 'lock',
akerun_id: 対象のAkerunコントローラーのID,
accessed_at: 入退室の時間(ISO 8601形式),
}
slack側で設定していきます

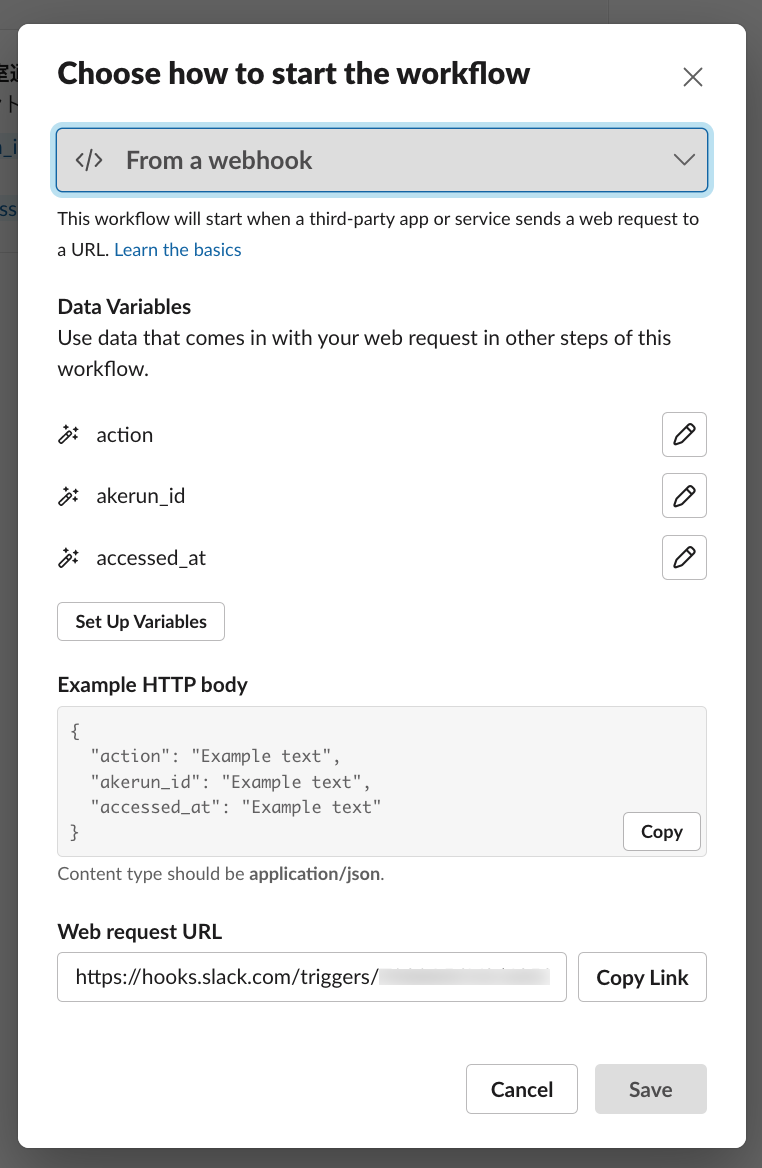
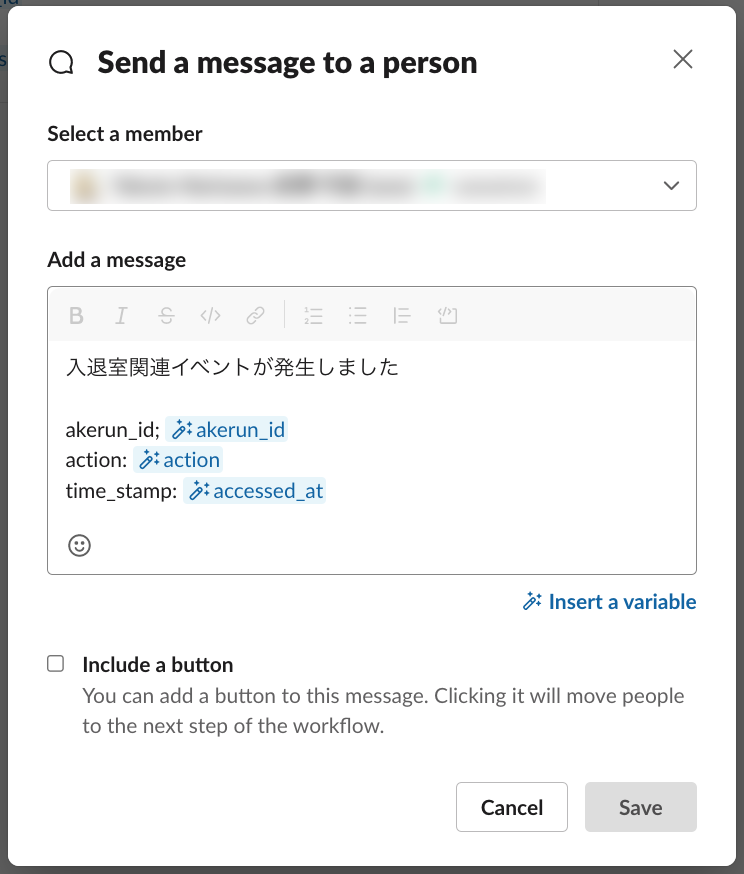
条件分岐など、細かい設定はできませんが、変数をメッセージに埋め込めば、毎回異なるメッセージを通知できます。
まずはcurlでデータを渡して動作確認です
curl -X POST -H "Content-Type: application/json" -d '{
"action": "lock",
"akerun_id": "R12XXXXXXXX",
"accessed_at": "'$(date -u +'%Y-%m-%dT%H:%M:%SZ')'"
}' 'https://hooks.slack.com/triggers/XXXXXXXXX/YYYYYYYYYYYYY/ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ';
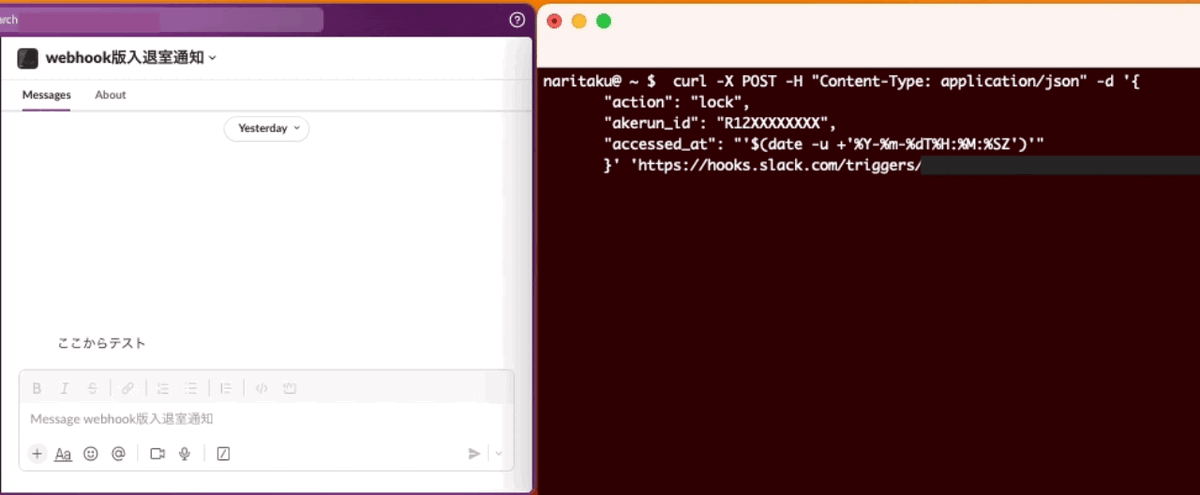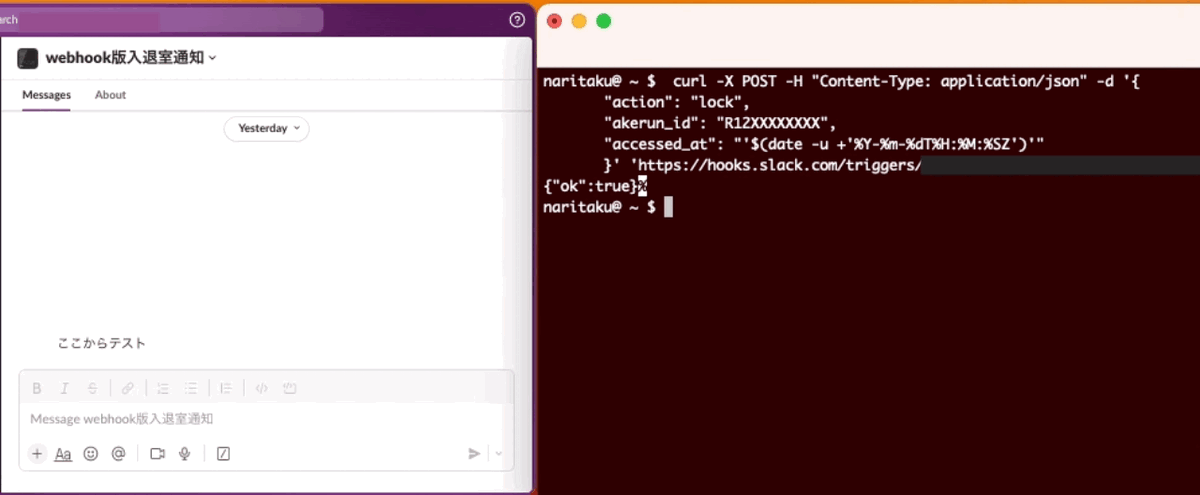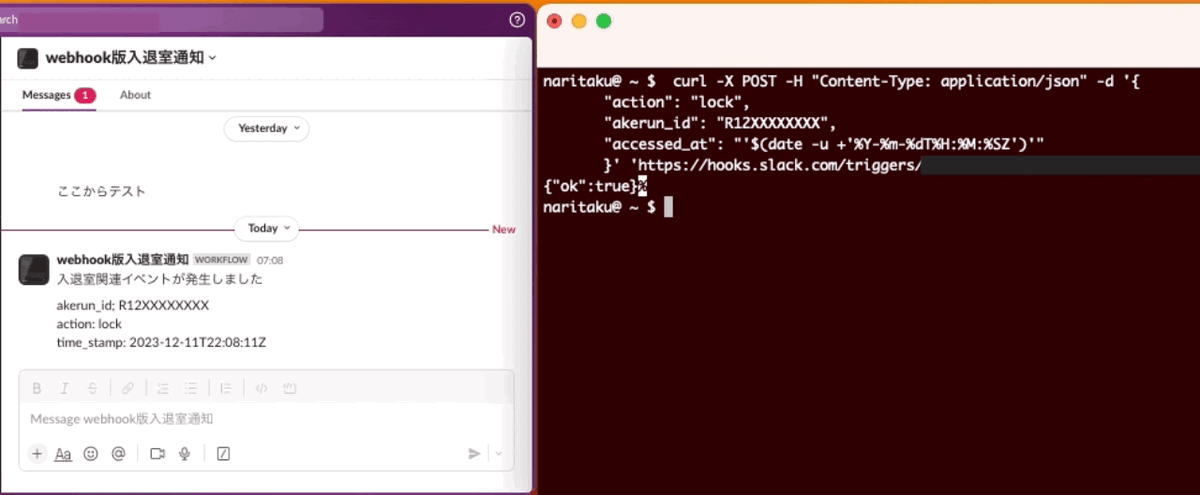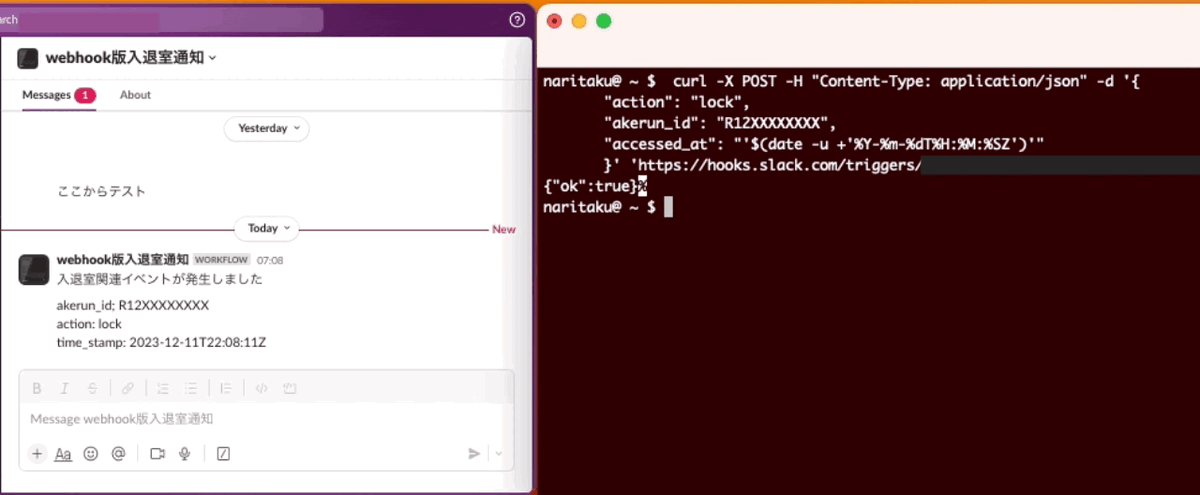
動きましたね!
実際の施解錠のロジックに埋め込み、CTLの中から直接postできるようにします。

しっかり通知できました!
所感
slack workflowと繋いでみて
サービスと連動させるために設定もシンプルで、想像よりも速く簡単にできました。
実際に動かしてみて、ICカードリーダーへのレスポンスとほぼ同じタイミングで通知できるのは心地よかったです。
製品の機能にするなら
webhookによって様々な機能と連携できる反面、多くのユースケースを満たせるような設計が肝になりそうです。
- シンプルに開閉だけが取れれば良い(今回作ったもの)
- 履歴取得で取れる相当の詳細な開閉ログを毎回通知してほしい
- 開閉の履歴は必要ないが、未登録のカードでの開閉失敗だけを知りたい
パッと思いつくだけでも色々ありますが、これらに合わせて、なりすましの対策や通知できなかった時のバックアッププラン、なども考える必要があります。色々詰め込むとどんどん複雑に見えてきますね。設計が大変そう。
最後に
webhookを使ったakerunコントローラーとslackworkflowの連携を試しました。
拡張性が高く、弊社が既に提供しているAkerun APIとも親和性が高く感じました。
ブログを書きながら色々試している過程が楽しかったです。
リアルタイムに連動するものが増えるとワクワクしますし、フォトシンスの目指すキーレス社会の実現にも一歩近づくのではないでしょうか?
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com