Androidアプリ開発でREST APIのモックサーバーを用意する方法
こんにちは、ohioshirt - Qiita です。
今回は、業務効率化ツールの話です。
モバイルアプリの開発中に
色々なレスポンスを返して欲しくなることがあります。
例えば、課金ユーザーとそうでないユーザーで
レスポンスの形式を変えたいとか、
所属しているグループの状態によってレスポンスの形式を変えたいとか。
もちろん、サーバー/DB側で
それぞれの状況に応じたアカウントを作っておくのが一番ですが、
それなりに手間がかかるので、
ダミーのAPIサーバーからレスポンスを返すようにして
済ませることがあります。
これまで扱ってきた方法の変遷を振り返ってみます。
いずれも新しいものではないので紹介は軽めにします。
その1:RetrofitMock
Retrofitは、Androidアプリでよく使われるHTTPクライアントです。
RetrofitMockは、そのRetrofitのモック機能です。
しかし、手軽さに劣るせいか最近はほとんど使わなくなりました。
現在の出番はテストコードを書くときくらいでしょうか。
その2:Prism
Prismは、OpenAPIのモックサーバーです。
OpenAPIは、APIの仕様を記述するためのフォーマットです。
OpenAPIのフォーマットでAPIの仕様を記述すると、
Prismがそれに従ってレスポンスを返してくれます。
弊社はOpenAPI仕様に基づきドキュメントを作成しているので、
そのopenapi.yamlを使って起動するだけ準備完了です。
任意の値が必要になれば、openapi.yamlを修正して
exampleの値を変更します。ほとんどの場合はこれで事足ります。
JSONファイルを指定してもいいです。
日々ドキュメントをメンテナンスされているからこそできることですね。
Prismは、開発PCで動作させることがほとんどであるため、APIサーバーとは別のリクエスト先になります。
この辺の設定をアプリ内でどう定義するかはチーム次第ですが、
開発用のビルドはAPIのURLを動的に変更できるようにして、
そこにモックサーバーを動作させているURLを設定できるようにすると便利だと思います。
その3:Ktor Server
Ktorは、Kotlinで書かれたWebアプリケーションフレームワークです。
Androidアプリ上でも動かすことができるので、
開発用のスマートフォン一台で完結します。
https://ktor.io/docs/create-server.html
サーバーアプリの作成
せっかくなので現在の作り方をなぞってみます。
まずは、Androidアプリプロジェクトを作成します。
Ktorを使うために、dependenciesに以下を追加します。
(最近使うようになったVersion Catalog形式で)
[versions]
ktor = "2.3.7"
[libraries]
ktor-server-core = { group = "io.ktor", name = "ktor-server-core", version.ref = "ktor" }
ktor-server-netty-jvm = { group = "io.ktor", name = "ktor-server-netty-jvm", version.ref = "ktor" }
次に、アプリ上でKtorのサーバーを起動します。 高い品質を求められない状況であれば、シンプルに以下のように書けばOKです。 楽に書きたいので、KotlinのCoroutineを使います。
// MainActivity.kt override fun onCreate(savedInstaneState: Bundle?) { // ... lifecyclescope.launch { embeddedServer(Netty, port = 8080) { routing { get("/") { call.respondText("Hello, world!") } } }.start(wait = true) } }
これで、http://localhost:8080/ にアクセスすると
Hello, world! と表示されます。
実際に投入するには、以下のようにもう少し複雑なルーティングの定義や制御が必要があるでしょう。
- APIドキュメントからエンドポイントを抽出してルーティングを定義する
- APIドキュメントに書かれているサンプルのレスポンスのJSONをアプリ内のassetsに保存しておき、 リクエストに応じて読み込んで返す
- より柔軟にレスポンスを返すために、 リクエストパラメーターに応じてレスポンスを生成する
- 全体で一貫性をもたせるために、DBを使ってレスポンスを生成する
- サーバーアプリ自身で値を変更できるようにする
後半はやりすぎかもしれません。もはやローカルでWebアプリのコンテナを動かす方がいいとすら思えます。
ただ、データの定義はquicktypeを使うことで
JSONからデータクラスを生成でき、
固定のデータを返すだけだった動作から拡張性が向上します。
業務を快適にするためのツールを作るのは楽しいです。
もちろん、それが目的になっては意味がありません。
まだまだ改善の余地はありますが、
今後も時間を作って時間を作るための取り組みをしていきたいと思います。
次に何が欲しいかというと、Bluetoothの通信をエミュレートするツールです。
AkerunアプリはBluetooth通信を使ってAkerunを操作します。
その通信をエミュレートするツールがあれば、
より細かい制御ができるようになり、開発の効率や品質を上げられるでしょう。
先日の記事にもあるように、
通信相手の挙動を制御したい需要は各所にあるのだなと感じます。
これからも、業務を快適にするための活動を続けていきたいと思います。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
開発遅延を防ぐ!事前検証によるプロジェクト管理術
この記事は Akerunのカレンダー | Advent Calendar 2023 - Qiita の 14 日目です。
こんにちは、オフィス開発チームの ps-shimizu - Qiita です。普段はRuby on Railsや Golang での開発をメインにしています。 最近はプロジェクトマネージャーとしても活動を始めて、技術と管理の両面からプロジェクト成功の秘訣を模索しています。
今回は初期段階での検証がなぜ重要か、どうやって実施するかをお話しします。
はじめに
プロジェクトの初期段階での検証は、将来的な問題を未然に防ぐために重要です。 この段階での検証は、設計や実装フェーズでの手戻りを減らし、結果として開発プロジェクトの Quality / Cost / Delivery のバランスを保つことに繋がります。
なぜ事前検証が重要か

プロジェクト初期での事前検証が重要なことは読者の皆さんもご存知だと思います。 この検証が重要な理由は、開発初期に検証を行うことで、リスクや性能のボトルネックを早期に発見できる点です。これにより、リスクや性能改善のための対策を素早く実施することが可能となります。
事前検証を効果的に行うためには適切なリソース(スケジュールや予算)や予算の確保が重要です。検証プロセスに必要なスケジュールや予算をあらかじめ、計画に組み込むことで実施に必要な精度と焦点を保つことができます。事前検証は単なる前準備というよりは、プロジェクトの品質と成功を保証するための投資と考えることが重要です。適切なリソースを確保することで、検証が十分に行われ、その結果をもとにした効果的な対策を講じることができます。
早期にリスクや性能改善の対策を講じておくことで、設計・実装フェーズでの予期せぬ問題によってプロジェクトの遅延や開発コストの増加を未然に防ぐことが可能になります。
少々地味な作業かもしれませんが、プロジェクトのQCDを一定水準満たすために欠かせないプロセスです。
失敗談

読者の皆さんも開発途中にリスクやパフォーマンスに問題があることが発覚し、それによって開発が遅延した経験があるのではないでしょうか?
私自身もプロジェクトの初期段階での事前検証の重要性を理解しておらず、事前検証を実施しなかった経験があります。その結果、設計・実装フェーズでリスクやパフォーマンスに問題があることが発覚し、発覚したリスクの対応やパフォーマンスチューニングを追加で実施することになり、結果開発が大幅に遅延し当初予定していたリリース日に成果物をデプロイできなかった経験があります。
失敗してから変えたこと
開発初期段階に十分なリソースを確保した上で事前検証を実施するようになりました。事前検証は開発内容やプロダクトによって検証内容が異なりますので、ここでは私が直近実施した事前検証の例を紹介します。
事前検証の実施例

事前検証の要なのは「本番相当の環境」で検証を実施することです。 本番相当の環境で検証を実施することで、本番環境で発生するリスクやパフォーマンスの問題を事前に発見することができます。
例1 | クエリのパフォーマンス検証
よくある例です。 クエリを新たに追加するもしくは既存のクエリを改修するのであれば、本番相当のデータ量のあるDBに接続し、追加するクエリの実行計画を取得するかつ実行時間を計測します。 本番でクエリを実行するとリスクがあるようであれば検証環境で本番と同等のレコード量を用意し、クエリの実行計画を取得し、実行時間を計測します。
事前にクエリの性能を確認しておくことで、開発初期にクエリの改修や別のロジックを検討することが可能となります。
例2 | メール送信処理のパフォーマンス検証
新たに機能を追加するのであれば、追加する機能のパフォーマンスを検証するために、本番相当の環境でパフォーマンステストを実施します。 私が直近検証したのは、メール送信処理が所定の時間内に完了するかを開発初期段階で検証しました。仮に、メール送信対象のユーザ数が5000ユーザいたとして「所定の時間以内に5000ユーザに対してメール送信が可能か?」という検証です。
検証の結果、メール送信処理が時間内に完了することは確認できましたが、仮に「メール送信が所定の時間内に終わらない」ということが発覚した場合、開発初期にメール送信処理のロジックをかえるもしくは別の仕組みでメール送信を検討することが可能となります。
例3 | 初導入の技術の検証
初導入の技術の検証でも同じことが言えます。 直近、新たにRedisを既存のAPIに導入するプロジェクトに携わりましたが、APIとRedisのパフォーマンス検証を開発初期に実施しました。 検証内容は、Redisを利用するAPIに対して本番同等に分間15000回リクエストし
を検証しました。 結果はRedis / APIともに十分にパフォーマンスが発揮できることを確認できましたが、 仮にRedis / APIどちらか一方でもパフォーマンスが出ない場合は別の仕組みやロジックを検討する必要があります。
開発初期に事前検証を取り入れた結果
開発スケジュールが遅延した経験を経てからいくつかの開発プロジェクトに携わっていますが、プロジェクト初期に十分にリソースを確保した上で検証を実施するようになってから、未然にリスクやパフォーマンス問題を検知できるので「実装フェーズでリスクやパフォーマンス問題が発覚し追加の対応を実施する」ケースが減り、結果開発スケジュールが前倒しもしくはオンスケジュールで開発を進行できるようになっています。
開発が前倒しやオンスケジュールで進行している要因は、開発初期に不確実性を解消することで、 設計や実装フェーズでの手戻りも少なくなり結果、予測しにくい追加開発が発生しくくなっているためです。
まとめ
今回は事前検証がなぜ重要か、どうやって実行するかを私の失敗談や事例を交えてお伝えしました。事前検証は地味な作業ではありますが、プロジェクトの初期段階で不確実性を減らす強力なツールになります。
適切な検証プロセスを設計し実行することで、プロジェクト進行における不確実性を減らし、問題が発生するリスクを軽減することができます。プロジェクトの成功に向けて、ぜひ事前検証を活用してください。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
レガシー製品のリファクタリング戦略
この記事は Akerunのカレンダー | Advent Calendar 2023 - Qiita 6日目の記事です。
ishturk - Qiita です。 この記事ではエンジニアが大好きなリファクタリングについて綴ります。
リファクタリングの理由
ソフトウェアには必ず不具合が潜んでいます。ハードウェアを制御しているソフトウェアだと、タイミングや外的要因(温度や経年劣化など)で発生率が大きく変わったりします。 これまでも、お客様に迷惑をかけないために、検知した不具合をスピーディに修正するサイクルを回してきました。
その一方で、修正を繰り返した結果、当初の設計が歪み、あらたな不具合を埋め込んでしまうという問題が発生してしまいました。具体的には、単一責任の原則・開放閉鎖の原則に則っておらず、機能に影響する調査対象が多いこと、影響範囲が閉じないことをどうにかしないと打破できないと判断しました。
リファクタリングの戦略
1. ターゲットとなる品質問題を定義する
絶対に直すもの・直さないもの を明確にしプロジェクトKPIとします。
エンジニアは目についたものは全部直したくなります。リファクタリングしていいよ? というと、水を得た魚のようにたくさんのアイディアを出してくれます。
そこは品質問題になってないから、やりません。をチームで明確に決め、直さないものを決めることも非常に重要です。
2. メトリクス:モジュールごとに潜在不具合リスクを定量化
モジュールごとに以下の指標で不具合リスクを定量化し、上位をピックアップしました
- 行数
- 複雑性
- 変更回数
行数・複雑性の可視化
プロダクトコードがJavaScriptで書かれていたため、 plato - npm を利用して静的解析をかけてみました。
行数と複雑性は明らかに正の相関がありました。また、platoが Estimated errors in implementation なる値を出してくれました。傾向がほぼ Lines of code と同じなので、何らかの計算式で正規化しているのでしょう。



変更回数の可視化
過去に不具合修正・デグレを繰り返していることから、変更回数の多いモジュールが品質リスクが高いと考えられます。
変更回数の算出は Gitで更新頻度の高いファイルを見つける方法 - アジャイルSEの憂鬱 が参考になりました。
以下のコマンドを実行して git で取得しました。
git log --name-only --oneline --diff-filter=M --since='5 year ago' | grep -v ' ' | sort | uniq -c | sort -nr | head -n 20 | sed 's/^[ ]*//' | tr ' ' '\t'
実行結果は以下のようになりました。最上位は92回の変更がされていました。

3. 総合的に判断する
1・2 の内容を鑑み、ここは機械的な判断ではなく、シニアクラスのエンジニアが、どのモジュールをどうリファクタリングするか決定します。
- 行数・複雑性の高いモジュールの分割・構造変更
- ターゲットとなる品質問題の影響範囲を洗い出し、関連モジュールを単一責任の原則・開放閉鎖の原則に則った設計へ変更
今回は行数・複雑性の高いモジュールと品質問題を起こしていたコアモジュールが同一だったため、そのモジュールをどう分解するかが設計の肝となりました。
振り返り
正直なところ、分析するまでもなく、直したほうがよいモジュールはわかっていたし、変更の方針も概ね見当がついていました。 なので、メトリクスを可視化しなくても同じ結果には帰着できたかもしれません。
ただし、事前に問題を分析・ゴールを明確にすることで
- 設計者が惑うことなく設計できる。悩んだ際に目的に立ち戻ることができる。
- before/after で効果を計測できるため達成感が得られ、えらい人にも効果を説明しやすい。
- 継続的な改善の礎になる
という効果がありました。絶対やったほうがいいです。ハッピーリファクタリング。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
組み込みエンジニアのインフラ/SREへの挑戦
組み込みエンジニアのインフラ/SREへの挑戦
はじめに
みなさま、初めまして。昨年11月にphotosynthに中途で入社したny-yoです。よろしくお願いします。
今回は組み込みエンジニア出身の私が、インフラ/SRE領域に挑戦した1年を振り返りたいと思います。
なぜインフラ/SREに挑戦しようと思ったのか
なぜ組み込み出身の私が異なる領域に挑戦しようと思ったのか、私自身の思い、きっかけに絡めて紹介します。
私は新卒で某複合機メーカーに入社してから、組み込みLinux、デバイスドライバなどいわゆる低レイヤーソフトウェア開発に携わっていました。
これからの時代はデバイスとWebのシームレスな連携、「モノ」から「コト・体験」が重要になってくるIoT時代がどんどん加速していきます。
Photosynthは「デバイス」も「Web」も社内で開発しサービスを提供しているテックベンチャーの中でも非常に稀有な存在ではないでしょうか。そんなPhotosynthに入社して、「デバイス」と「Web」が重なり合う領域に携わりたいと考えていました。
また、ちょうど入社して少し経ったぐらいのタイミングで、開発部内でインフラ/SRE領域が人手不足でヘルプ要請があったのです。
なので、これはチャンスだと思い「自分でよければぜひやってみたい」と部長や上長に申し出てチャレンジしたのがきっかけです。
挑戦してみての印象
勢い勇んで飛び込んでみて、サービスを支えているシステム裏側を支えている仕組みの複雑さに驚きました。
「鍵」という重要なセキュリティインフラを扱っているため、サービス稼働の監視、バックアップ体制、インフラ冗長化など、書籍やネット記事で目にして、なんとなく理解しているつもりでも生きたサービスで実際に使われていることに改めて驚きましたね。
また自分が今まで知らなかったWeb関連のOSSなどたくさん使われているので、最初はかなり戸惑いました。(「nginx」の読み方がわからなかったのはいい思い出ですね。)
どんな業務をやってきたのか
実際の業務ですが、各種ツール/サービスのアカウント管理、サーバー管理、脆弱性対応、インフラ周り対応など幅広く携わることができましたが、中でもサーバーの「OSS/Middleware」脆弱性の負債返済と闘ってきた1年だったかなと思います。
PhotosynthのいくつかのサービスはAWS上に本番サーバーインスタンスを建ててWebアプリ等を稼働させているのですが、その当時課題となっていたのが、サーバーの「OSS/Middleware」バージョンアップです。
ソフトウェアも日々脆弱性が見つかったり潜在的なバグが見つかったりと日々のメンテナンス、更新の繰り返しが必要です。Photosynthで稼働しているサーバーもサービス稼働してから更新が滞っており、積み上がった脆弱性を潰していくのが、メインミッションでした。
とはいえ、実際の本番サーバーに対する作業はサーバーにssh等で入って、更新適用し、サーバーを再起動する
sudo yum update sudo reboot
たったこれだけのコマンドを打つだけです。これだけなんですが、更新を適用した後も問題なく稼働しているか、挙動がおかしくならないか、負荷トレンドが急上昇しないか、作業以上に確認すべきこと、注意することが多いです。
また、作業対象のサーバーも以前から稼働した状態で、どんなアプリケーションが動いているか、OSSは何を使っているのか全くわからないものを相手にする必要がありました。
なので、本番作業を迎えるにあたり毎回以下のことを必ず守るようにしてました。
- 稼働しているサービス、OSS、接続先、インフラ構成等、仕様を把握する(人に聞いたり、社内文書検索したり)
- STGで事前検証を入念に行う
- 更新対象のOSSのバージョン差分をよくみる(特に大きなバージョンアップはないか)
- 本番環境での手順書を作成、関係者にレビューいただく
- 実際の本番作業はからなず複数人で行う
- 万が一の時を備えてロールバックなどの手段を必ず用意する(更新前のイメージスナップショットを取得)
- 更新作業が終わった後も稼働状況や負荷トレンドをしばらく見守る
当たり前と言えば当たり前かもしれませんし、少々過剰気味な気もしますが、安定したサービスを提供し続ける、障害を発生させない、という観点ではこれぐらい慎重に対応するぐらいがいいかなと思います。
一方で現状はサーバーに直接入って、更新対象確認して、アップデートコマンド実行してと、まだまだ手作業が多いのも課題かなと感じています。
AWS Patch Managerでパッチ管理/自動化やE2Eテスト自動化などシステムに任せられるところは任せて、開発者の負荷を減らしながら、継続的な仕組みにできるとよりいいですね。
挑戦してみて、気づき
今までは開発者として「新製品、新機能、新サービス」を納期厳守でリリース、不具合があったら(渋々)修正する、など作っては世に出して、その後のアフターフォロや稼働状況はあんまり気にはしてなかったのが正直なところです。
今回初めて「開発」の立場から「運用保守」の立場になってみて、やはり自分たちが作って世に出したサービスが実際に使っていただくのは嬉しい、世に出して終わりではなく、ずっと使っていただくためにも日々の小さなメンテナンスやアフタフォローが大事だと改めて感じさせられました。
インフラ/SREはその職種立場上、他のサーバーやリソースにアクセスできたりと、より強い権限を持っています。だからこそ、古くからの格言でもある
「大いなる力には大いなる責任が伴う」
言葉を胸に刻んで、(特に本番環境では)緊張感をもって作業するようにしてます。
また、これは特にサーバーコンソール上で作業している時に頭の片隅に置いてるんですが、
「Think, before you type.」
コマンドのタイプミスが重大な事故になってしまったなど、よく耳にします。
コマンドを「カタカタ、ターン!」てやる前に一呼吸置くようにしてます。
これから
インフラ/SREに挑戦してみて、色々学ぶ機会が多く、より成長できた1年だったと個人的に思ってます。
未経験ながらもこのような機会を与えてくれた職場には感謝しつつ、これからもよいサービスを提供し続けられるように精進いたします。
今回は少し抽象度が高く一般的な内容にとどまってしまいましたが、
機会があれば、Photosynthならではの「Web」だけじゃない「デバイス」も絡めたインフラ/SREの難しさ、醍醐味なんかについても紹介できればと思ってます。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
開発組織の負債と戦い続ける
この記事は Akerunのカレンダー | Advent Calendar 2023 - Qiita の 11 日目です。
このイベントに参加して 4 年目となりました AkiAbe - Qiita です。
昨年は FW 開発領域のマネージャーとしての活動をしていましたが 、今年はソフトウェア領域全体のマネージャーとして活動をさせていただきました。
photosynth.co.jp
現職に拝命して、まず開発組織の立て直しに注力しました。
その過程で SaaS 事業を運営する会社の宿命として「組織/技術負債と戦い続ける覚悟」が必要だなと感じました。
組織的負債ってなんなん?
ChatGPT さんに聞いてみよう。

ふむふむ。
じゃあ技術的負債との違いはなんだろうか?

ですよね。リンクしてますよね。どちらも一緒に改善が必要ですね。
技術側はテックリードのエンジニアにお任せして、私の方は並行して組織的負債と向き合うことにします。
我々の組織コンディションはどうなの?
こちらから引用。 www.infoq.com
- 異なる部門で別のツールや方法論を使って同じ問題を解決している。それによって、上層部は企業全体の問題に対処するための同質性を見つけにくくなる。
- マネージャはその時に良いアイディアだと思ったプロセスを作り、ソフトウエアを実装するが、問題の根本には対処せず、その結果、長期的にはより問題が生まれる。
- 時間の短縮によって、チームは"今回は"あるタスクを理想的な時間よりも短い時間で仕上げようと決定する。しかし、このやり方が繰り返されてしまう。というのは、最初の1回が特別だったことを誰も覚えていないからだ。
いやーあるあるですね。
我々ももれなく抱えていました。
過去の開発部組織体制は、技術領域ごとにグループをきっちり分けている状態でした。
そのため同じソフトウェア開発をしているのに文化、モチベーション、マインドセットがグループごとに違っている状態でした。
プロダクトとしてもコンウェイの法則が色濃く反映された状態でした。
特に顕著だなと思った一例を挙げます。
一時期、リポジトリの参照権限を各開発グループ/所属ごとに厳しく設定管理していました。
そのため、開発時に依存するライブラリを開発担当者が参照できず、リリースまでの時間的余裕もないという状態であったため、期日に間に合わせるために、無理やり内部リポジトリにそのライブラリを固定して持っているというプロダクトが存在しました。
まさしく、組織構造がそのままプロダクトに反映された例だと感じました。
組織的負債が技術的負債につながっている実例を見た気がしました。
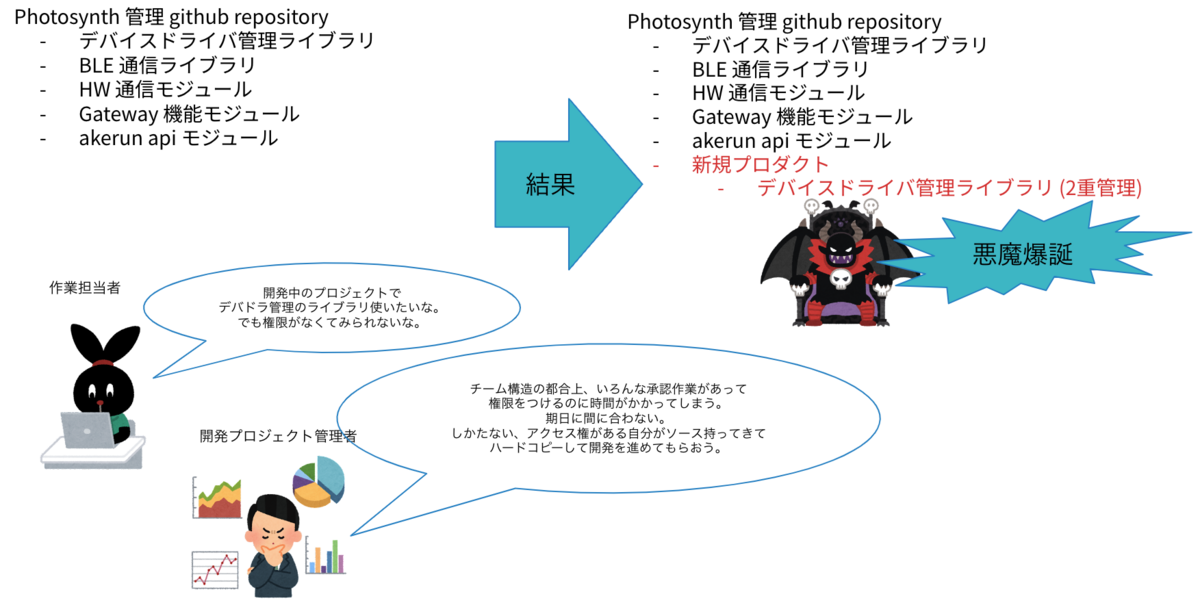
また、技術領域を超えたコラボレーションも少ない状態でした。
我々は IoT x SaaS という事業を展開しており、ハードウェア開発および組込ソフトウェア開発からクラウドサービス開発までカバーしています。
横を見れば自分が経験したことのない技術を扱っている人がいる状況にも関わらず組織を超えた技術領域に対する興味が薄い。興味があるが声をかけ辛い。みたいな状況が続いていました。
我々の規模 (開発部以外も含めた全従業員数 160 名程度) の会社でこれだけ広い技術領域をカバーしたエンジニアが在籍する企業は世間を見てもそんなに多くないと思うので、すごくもったいないなぁと感じていました。
どう変えたのか?
上述した課題を解決すべく、組織構造を思い切って変えました。

賛否はあるのは承知ですが現時点で以下の狙いをもって活動しています。
- エンジニアが事業貢献に対する意識をより向上させる
- これから作るものが事業にどう影響するかの理解する
- 作ったるプロダクトに対する責任をもつ
- 技術領域を超えた交流のを促進させる
- 組込/web の相互プロダクト理解を進める
- システムとしてどういう設計であるべきかの議論をスムーズにする
- それぞれ独自に進化した文化を共有し合い、いいとこどりを目指す
併せて横串で技術領域を統括する基盤開発チームを作りました。
我々がキーレス社会を担うプラットフォーマーとして成長/運営し続けられるための共通基盤開発をメインにしてもらいます。
また、各事業で独自にプロダクト開発が進んだ際に、知らない間に共通基盤に魔改造が入り誰もメンテナンスできない状態になるのを防ぐ役割も担ってもらいます。
よくあるマトリクス組織の形に近づいた感じですね。
この組織変更と並行して、開発運用プロセスの再定義や運用サイクルの立て付け、仕組み化なども行いました。
その話はまた別途。
組織変更でどういう影響があったのか
概ねポジティブな影響が多いなと感じています。
特に情報の受け渡し、部門内の透明性は少し上がった印象です。
実際にエンジニアからもらったよかったフィードバック
- 開発プロジェクト関連者が見えやすくなった。相談しやすくなった
- 作業の依頼がしやすくなり業務がスムーズになった (旧組織だとチームを超えた依頼となり心理的ハードルが高かった)
- 次にどういう開発案件が待っているのかみえるようになった
- 上述で例にあげたような技術的負債の一部解消も進んだ
逆に悪かった (狙い通りいっていない) フィードバック
- (1人 or 2人で完結するような) 小規模な開発プロジェクトが何本も並列している場合、お互いのやっていることの把握が難しい
- 案件がたくさんはしっていて QA エンジニアとのコラボレーションが進まない
- 横串活動の技術リーダーの負荷が高い
という感じでした。
案件がたくさん走っている状態だと横串部門への相談が増える傾向にありました。
会社方針として「小粒な案件を大量に捌いていきたい」という状況ではこのような組織構成は向いていないのかもしれません。
どんな組織が最適なのか?は会社のフェーズ、事業内容によっても変わってくることだと思います。
その時々の開発チームコンディションも加味する必要があります。
現時点ではこの体制で特に大きな問題はないと感じていますが、来年になったら違うことをいうかもしれません。
会社も組織も生き物ですので、柔軟にやっていけるとよいかなと感じています。
これからも安定したサービスの提供と、新しく価値のあるプロダクトを生み続けられる開発組織を目指して試行錯誤していきたいと思っています。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
Cobraを使ったCLI開発の新しい定番 ~ベストプラクティスと実践ガイド~
この記事は Akerunのカレンダー | Advent Calendar 2023 - Qiita 15日目の記事です。
こんにちは、住宅開発チームの島田です。
はじめに
今回は、Go言語でCLI(Command Line Interface)を実装した際の課題とそれに対するアプローチを紹介したいと思います。
CLIで実現したい事は、以下の内容になります。
- 管理者ユーザをDBに登録する
- CLIのパラメーターで登録するメールアドレスを受ける
- 登録ができたら、登録したメールアドレスにメールを送信する
パッケージを利用しないパターン
Go言語にはCLIを実装するための便利なパッケージがいくつかありますが、それらを利用しないでまずは実装をしてみました。
batch/create_admin_user/main.go
// 以下のコードサンプルは概念的なアイディアを示すものであり、 // この例では実際に動作するコードではありません。 package cmd import ( "errors" "flag" "os" ... "gorm.io/gorm" ) var ( mailAddress string ) func init() { flag.StringVar(&mailAddress, "mail", "", "登録するメールアドレス") } func main() { err := createAdminUser() if err != nil { os.Exit(1) } err = middleware.NewMailMiddleware().SendMail(mailAddress) if err != nil { os.Exit(1) } } func createAdminUser() error { flag.Parse() err := validateArgs(mailAddress) if err != nil { return err } con := db.NewDB(&gorm.Config{}, "default") defer db.CloseDB(con) adminUser := &repository.AdminUser{ Mail: mailAddress, } return con.Model(&repository.AdminUser{}).Create(adminUser).Error } func validateArgs(mailAddress string) error { if mailAddress == "" { return errors.New("mailAddress is required") } return nil }
上記のコードは要件を満たしています。
しかし、CLIが増えた場合に以下のような課題を孕んでいます。
- 同じような実装が散在する(DBのコネクション処理や引数のバリデーションなど)
- エラー終了などのハンドリングなどの統一を強制できない
- テストコードでmiddlewareをmockにしたい場合に実装の外部から置き換えることができない
これらの課題を解消するために、CLIの実装に対して統一的なアプローチを強制できるように、CLIパッケージの導入しました。
CLIパッケージの選定
Go言語で代表的なCLIパッケージである以下の2つを比較しました。
どちらも、
- インタフェースがシンプルで、簡単に導入できる
- 導入事例が多くある
- ドキュメントを含めて、メンテナンスが継続的にされている
でした。
現時点では、Cobra の方がやや導入事例が多かったのと、urfave/cli のv3 alphaがリリースされており今後の変更が考えられたので、Cobraを採用しました。
Cobraを利用したパターン1
構成は以下のようになります。
batch ├── cmd │ ├── adminUser.go │ └── root.go └── main.go
main.go と cmd/root.go は、 $ cobra-cli initで生成したままの構成です。
batch/main.go
package main import "github.com/Photosynth-inc/example.git/cmd" func main() { cmd.Execute() }
batch/cmd/root.go
package cmd import ( "os" "github.com/spf13/cobra" ) var rootCmd = &cobra.Command{ Use: "cmd", } func Execute() { err := rootCmd.Execute() if err != nil { os.Exit(1) } }
batch/cmd/admin_user.go
以下のコードが先ほどのCLIをCobraで置き換えたものになります。
package cmd import ( "github.com/Photosynth-inc/example.git/pkg/db" "github.com/Photosynth-inc/example.git/pkg/middleware" "github.com/Photosynth-inc/example.git/pkg/repository" "github.com/spf13/cobra" "gorm.io/gorm" ) var adminUserCmd = &cobra.Command{ Use: "adminUser", RunE: func(cmd *cobra.Command, args []string) error { mailAddress, _ := cmd.Flags().GetString("mail") err := createAdminUser(mailAddress) if err != nil { return err } err = middleware.NewMailMiddleware().SendMail(mailAddress) if err != nil { return err } return nil }, } func init() { rootCmd.AddCommand(adminUserCmd) adminUserCmd.Flags().String("mail", "", "mail address.") adminUserCmd.MarkFlagRequired("mail") } func createAdminUser(mailAddress string) error { con := db.NewDB(&gorm.Config{}, "default") defer db.CloseDB(con) adminUser := &repository.AdminUser{ Mail: mailAddress, } return con.Model(&repository.AdminUser{}).Create(adminUser).Error }
Cobraで置き換えたことによって、
- CLIの実装を統一したインタフェースで実装することが出来る
- 引数のバリデーションをシンプルにできる
といった事が享受できます。
しかし依然として、残ったままの課題があります。
今度はさらにリファクタリングをすすめて課題を解消したいと思います。
Cobraを利用したパターン2
batch/main.go
異常終了時の戻り値のハンドリングを元々は cmd/root.go でしていまたが、エラー発生時に os.Exit をしてしまうと、 defer が実行されないため main.go に移動しました。
package main import ( "os" "github.com/Photosynth-inc/example.git/cmd" ) func main() { err := cmd.Execute() if err != nil { os.Exit(1) } }
batch/cmd/root.go
- 共通化してサブコマンドで個別に実装しないようにした点
- PersistentPreRun , PersistentPostRun に実行時のコマンド名を出力
- データベース接続の初期化処理
- ログに一連のコマンド実行時のログだとわかるように、一意のIDをContextに設定してコマンドの実行時に渡す
package cmd import ( "context" "github.com/Photosynth-inc/example.git/pkg/db" "github.com/Photosynth-inc/example.git/pkg/config" "github.com/google/uuid" "github.com/spf13/cobra" "gorm.io/gorm" ) var rootCmd = &cobra.Command{ Use: "cmd", PersistentPreRun: func(cmd *cobra.Command, args []string) { fmt.Println("start cmd", cmd.Name()) }, PersistentPostRun: func(cmd *cobra.Command, args []string) { fmt.Println("end cmd", cmd.Name()) }, } func Execute() error { con := db.NewDB(&gorm.Config{}, "default") defer func() { d, _ := con.DB() d.Close() }() adminUserBatch := NewAdminUserBatch(con) rootCmd.AddCommand(adminUserBatch.NewCommand()) ctx := context.WithValue(context.Background(), config.CTX_KEY_BATCH_ID, uuid.New().String()) return rootCmd.ExecuteContext(ctx) }
batch/cmd/admin_user.go
middleware をテスト実行時にmockに置き換えることが出来るように、 cobra.Command の生成を構造体でラップしました。
package cmd import ( "github.com/Photosynth-inc/example.git/pkg/middleware" "github.com/Photosynth-inc/example.git/pkg/repository" "github.com/spf13/cobra" "gorm.io/gorm" ) type MailMiddleware interface { SendMail(to) error } type AdminUserBatch struct { db *gorm.DB mailMiddleware MailMiddleware } func NewAdminUserBatch(db * gorm.DB) *AdminUserBatch{ return &AdminUserBatch{ db: db, mailMiddleware: middleware.NewMailMiddleware(), } } func (b AdminUserBatch) NewCommand() *cobra.Command { cmd := &cobra.Command{ Use: "adminUser", RunE: func(cmd *cobra.Command, args []string) error { mailAddress, _ := cmd.Flags().GetString("mail") err := b.createAdminUser(mailAddress) if err != nil { return err } err = b.mailMiddleware.SendMail(mailAddress) if err != nil { return err } return nil }, } cmd.Flags().String("mail", "", "mail address.") cmd.MarkFlagRequired("mail") return cmd } func (b AdminUserBatch) createAdminUser(mailAddress string) error { adminUser := &repository.AdminUser{ Mail: mailAddress, } return b.db.Model(&repository.AdminUser{}).Create(adminUser).Error }
batch/cmd/admin_user_test.go
サブコマンドの生成を構造体でラップすることで、以下のようにテストコードでDBの接続先をテストDBにしたり、メール送信をmockにするといった事が可能になりました。
package cmd import ( "context" "os" "testing" "github.com/Photosynth-inc/example.git/pkg/mocks" "github.com/Photosynth-inc/example.git/pkg/test_util" "github.com/stretchr/testify/assert" "github.com/stretchr/testify/mock" ) func TestAdminUserBatch(t *testing.T) { db := test_util.ConnectTestDB() defer test_util.CloseDB(db) mockMiddleware := new(mocks.MailMiddleware) mockMiddleware. On("SendMail", mock.AnythingOfType("string")). Return(nil) batch := &AdminUserBatch{ db: db, mailMiddleware: mockMiddleware, } os.Args = append(os.Args, "adminUser") os.Args = append(os.Args, "--mail") os.Args = append(os.Args, "test@example.com") cmd := batch.NewCommand() err := cmd.ExecuteContext(context.Background()) assert.NoError(t, err) }
以上が、Cobraを利用したCLI実装の課題と改善アプローチの紹介でした。
CobraはCLI実装に対して非常に強力なパッケージでありますが、 cobra.Command の生成と実行は柔軟に出来るので、今回紹介した以外にも課題に対するアプローチは他にもあると思いました。
もし他にも良いアプローチがあればフィードバックをいただけると嬉しいです。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com
Google Play Consoleの署名エラーでリリースが遅れた
この記事は Akerunのカレンダー | Advent Calendar 2023 - Qiita - 9日目の記事です。
こんにちは、ohioshirt - Qiita です。
普段はAndroidアプリの開発をしています。個人ではiOSアプリも開発します。
今回はAndroidアプリリリース作業の中で起きたトラブルについて書きます。
はじめに
この記事にはアプリへの署名の話が出てきます。
記事そのものを読むための前提知識は不要だと思いますが、
知識を得たい場合は公式ドキュメントを当たってください。
https://developer.android.com/studio/publish/app-signing?hl=ja
実例に近い形で理解を深めたい場合は、以下の記事が参考になります。
https://note.com/nttrtech/n/n18280473a4d6
TL;DR
Google Play Consoleでアプリを更新しようとしたところ、署名エラーが発生して公開時の審査へ進めなくなりました。
こちらの不手際である確証はないものの
Google Issue Trackerで問い合わせたところ、
何かしらの修正が行われ、解決しました。
めでたしめでたし。
以下、本編です。
見知らぬ、エラー
ある秋の日のこと、
Google Play Console上で次のリリースに向けてアプリを審査に提出した時に
以下のエラーメッセージが表示されました。
以前の APK の署名には鍵のローテーションが使用されていますが、
このリリースには、proof-of-rotation に同じ証明書が含まれていない APK(バージョン コード xxxxxx)へのアップグレード パスが導入されています。
検索、そして検証
前のバージョンと比べてもtargetSdkVersionの変更も行っておらず、
署名に関する変更を行ったのは半年近く前のことです。
心当たりが無いため、ひとまず前例がないか調べてみると、
以下のコミュニティページが見つかりました。
ほぼ同じタイミングで同じエラーに遭遇した人がいるようです。
しかも、同じ問題があるという投票がいくつかありました。当時は2件ほどでした。
コメントから、おおよその条件が見えました。
- Playアプリ署名を有効にしている
- 鍵のローテーションを行った
- いわゆるAndroid13対応済み(targetSdkVersionを上げている)
なるほど、確かに該当する。
弊社も数ヶ月前に発生した某サービスのインシデントのために鍵のリセットを行い署名を更新しました。
しかし、それまで何の問題もなくアプリを更新できていたことから、
アップグレード自体は問題ないと考えていました。
ところが実際にapksignerで内容を確認すると、Scheme v3.1に違いが見られました。
pc-user@mac-user-san ~ % <path-to-apksigner> verify -v /Users/pc-user/work/10001.apk Verifies Verified using v1 scheme (JAR signing): false Verified using v2 scheme (APK Signature Scheme v2): false Verified using v3 scheme (APK Signature Scheme v3): true Verified using v3.1 scheme (APK Signature Scheme v3.1): true Verified using v4 scheme (APK Signature Scheme v4): false Verified for SourceStamp: true Number of signers: 1 pc-user@mac-user-san ~ % <path-to-apksigner> verify -v /Users/pc-user/work/10000.apk Verifies Verified using v1 scheme (JAR signing): false Verified using v2 scheme (APK Signature Scheme v2): false Verified using v3 scheme (APK Signature Scheme v3): true Verified using v3.1 scheme (APK Signature Scheme v3.1): false Verified using v4 scheme (APK Signature Scheme v4): false Verified for SourceStamp: true Number of signers: 1
Scheme v3.1がtrueとなり、今回のバージョンから差が生じたようです。
そして、今回のapkには先述のエラーに出てきた「proof-of-rotation」が正しく設定されていない模様。
どこかで設定する機会があったのか振り返ってみましたが、やはり無い。
初めてのIssue Tracker
原因と解決策が見つけられないため、サポートに問い合わせることにしました。
普段サポートに問い合わせることはないため、
適切な対応ができる問い合わせ先を特定するまでに時間がかかりました。
最終的にGoogle Issue Trackerに行き着いたものの、
これまで利用したことがないUIにまた苦労しました。

終息
問い合わせてからの動きは迅速でした。
1日足らずで返信があり、解決したとのこと。
Google Play Consoleを確認すると、エラーは解消され無事審査へ進めるようになっていました。
原因についての説明がなく真相は不明ですが、何かしらの対応が行われたと思われます。
はっきりしない終わり方ですが、 一連のエラー対応はこれで終息しました。
残された謎
改めてサポートページを見直すと
鍵のアップグレードを行う時にproof-of-rotation を生成することについて書かれていました。
ステップ 1: 新しい鍵をアップロードし、proof-of-rotation を生成してアップロードする
当時の手順とスクリーンショットを見る限り、
鍵をリセットした時にproof-of-rotationの設定を促されず
そのまま設定する機会が失われたのではないかと思います。
先のコミュニティページでのコメントを見る限り
Play Console側にも発生の原因があることが仄めかされていましたが、
はっきりとしたことはわかっていません。
よかったこと
Issue Trackerは滅多に使わないので、いい経験になりました。
意外とレスポンスが早く、たらい回しにされることもなく
心理的なハードルが下がりました。
また、原因調査の過程で署名に関する理解が深められたのも怪我の功名です。
反省点
今回のエラーの解決のために公開がそれなりに遅れました。
ビジネスサイドからの要望に応えるリリースが遅れてしまったことで、
関係者には迷惑をかけてしまいました。
不測の事態でもなるべく影響を広げないように、知識を深め迅速に対応していきたいです。
もう1点、リリース担当者(自分)がインフルエンザにかかってしまったことで
ストア公開はさらに1週間遅れました。
忘年会シーズン真っ只中、体調管理には気をつけましょう。
株式会社フォトシンスでは、一緒にプロダクトを成長させる様々なレイヤのエンジニアを募集しています。 photosynth.co.jp
Akerunにご興味のある方はこちらから akerun.com